LLM2Vec이라는 decoder-only LLM을 text encoder로 변환하는 unsupervised approach를 제안함.
- unsupervised approach는 아래와 같음
- causal attention을 bidirectional attention으로 전환하고, unsupervised manner로
masked next token prediction을 학습하여 llm을 적응시킴.
SimCSE 방법을 이용하여, unsupervised contrastive learning을 수행함.
- 결과는 아래와 같음.
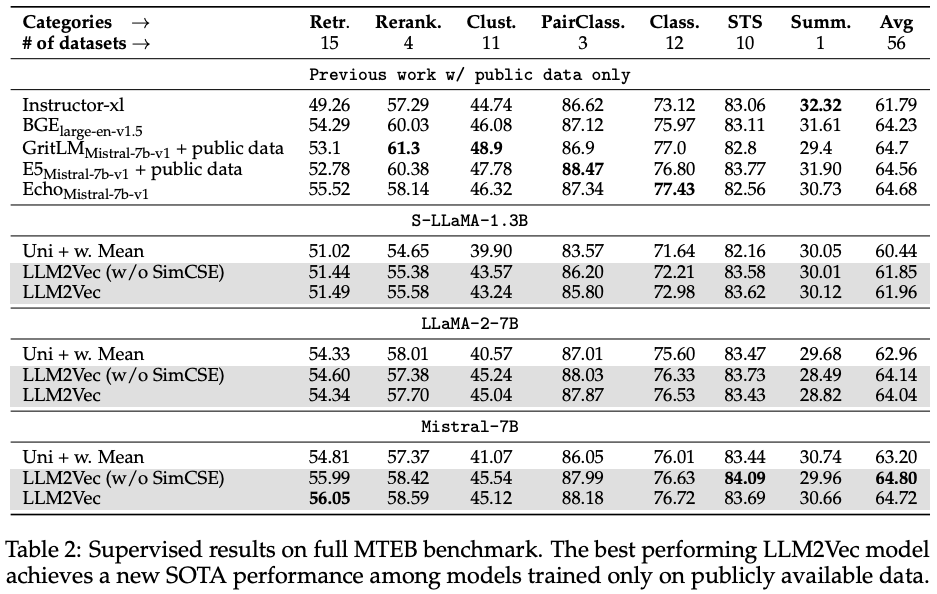
We demonstrate the effectiveness of LLM2Vec by applying it to 3 popular LLMs ranging from 1.3B to 7B parameters and evaluate the transformed models on English word- and sequence-level tasks. We outperform encoder-only models by a large margin on word-level tasks and reach a new unsupervised state-of-the-art performance on the Massive Text Embeddings Benchmark (MTEB). Moreover, when combining LLM2Vec with supervised contrastive learning, we achieve state-of-the art performance on MTEB among models that train only on publicly available data.
- decoder-only LLM은 causal attention 때문에 좋은 contextualized representation을 얻는 데 한계가 있음.
- 하지만 아래와 이유로 bidirectional attention을 사용하는 encoder model로 embedding을 얻는 거보다 매력적인 선택지임.
- encoder model보다 pre-training 과정에서 일반적으로 sample efficient함.
- decoder-only LLM에 관련된 연구 혹은 생태계가 상대적으로 잘 구축되어있고, 좋은 pre-training recipes (e.g. staged pre-training)이 많이 연구됨.
- decoder-only LLM의 instruction following 연구들에 힘입어, instruction을 사용해서 universal text embedding model을 만들려는 시도들이 있음.
- 어떠한 pre-trained decoder-only LLMs를 universal text encoder로 만드는 방법으로서
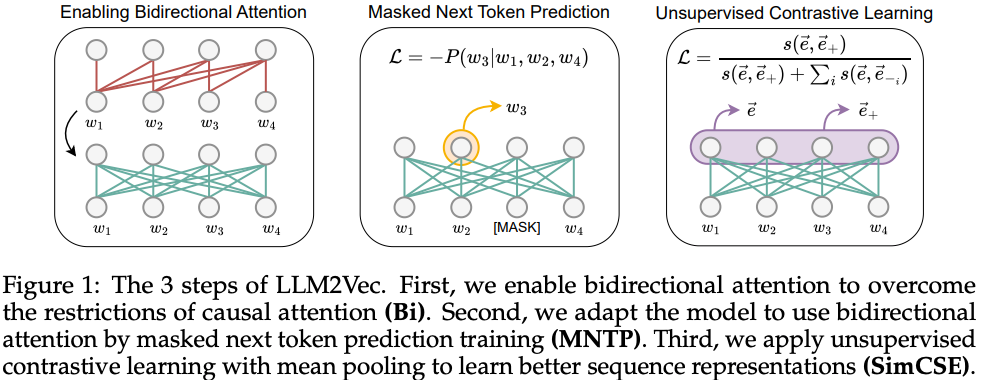
LLM2Vec을 제안함.As shown in Figure 1, LLM2Vec consists of three simple steps: 1) enabling bidirectional attention, 2) masked next token prediction, and 3) unsupervised contrastive learning. Crucially, LLM2Vec does not require any labeled data and is highly data- and parameter efficient.
Overall, our work demonstrates that decoder-only LLMs are indeed capable of producing universal text embeddings and only very little adaptation is required to reveal this ability.
- word-level tasks (e.g. chunking, named-entity recognition, part-of speech tagging) 뿐만아니라 sequence-level tasks (e.g. retrieval, classification 등)에서도 매우 좋은 성능을 보임. 또한 공개된 데이터셋만을 이용하여 supervised contrastive learning을 수행하면,
MTEB benchmark에서 SOTA 급 성능을 보임.
- decoder-only LLMs은 causal attention으로 학습되었으므로, bidirectional attention으로 inference를 하면 representation의 성능이 저하될 수 있음.
- 따라서
masked next token prediction (MNTP)로 학습하여, bidirectional attention에 decoder-only LLM이 적응할 수 있게해야함.Crucially, when predicting a masked token at position i, we compute the loss based on the logits obtained from the token representation at the previous position i − 1, not the masked position itself (see Figure 1).
masked next token prediction까지 끝나면, word-level tasks에 잘 대응하는 embedding model을 얻게된 것과 같음. → SimCSE를 사용하여 unsupervised contrastive learning을 해서 sequence-level tasks (e.g. retrieval, classification, clustering 등)에도 잘 대응할 수 있게함.
- sequence-level embedding을 얻고 싶은 경우,
mean pooling을 사용함.
Transforming decoder-only LLMs with LLM2Vec
- 아래의 세 개의 decoder-only LLMs를 사용함.
Sheared-LLaMA-1.3B (S-LLaMA-1.3B, Xia et al., 2023), Llama-2-7B-chat (LLaMA-2-7B, Touvron et al., 2023), and Mistral-7B-Instruct-v0.2 (Mistral-7B, Jiang et al., 2023).
MNTP와 unsupervised SimCSE에서 English Wikipedia만을 학습 데이터로 사용함.Specifically, we use the Wikitext-103 dataset (Merity et al., 2017) for the MNTP step and a subset of Wikipedia sentences released by Gao et al. (2021) for the unsupervised SimCSE step.
- decoder-only LLMs의 pre-training 과정에 포함되는 데이터이므로, adaptation하는 것외에 새로운 knowledge를 가르치지 않게 할 수 있음.
MNTP 과정에서 masking을 위한 special token이 없기 때문에, underscore (_)를 masking token으로 사용, LoRA를 사용하여 학습함.We fine-tune the model using LoRA (Hu et al., 2022) to predict the masked token using the representation of the previous token to maximally align our training objective with the pre-training setup of decoder-only LLMs.
SimCSE 방법을 LoRA를 사용하여 학습함.We merge the MNTP LoRA weights into the base model and initialize new LoRA parameters before starting the SimCSE training, which ensures that the model retains the knowledge learned in the previous step.
LLM2Vec-transformed models are strong unsupervised text embedders
Evaluation on word-level tasks
- linear probing setup으로 아래의 tasks에 대하여 평가함.
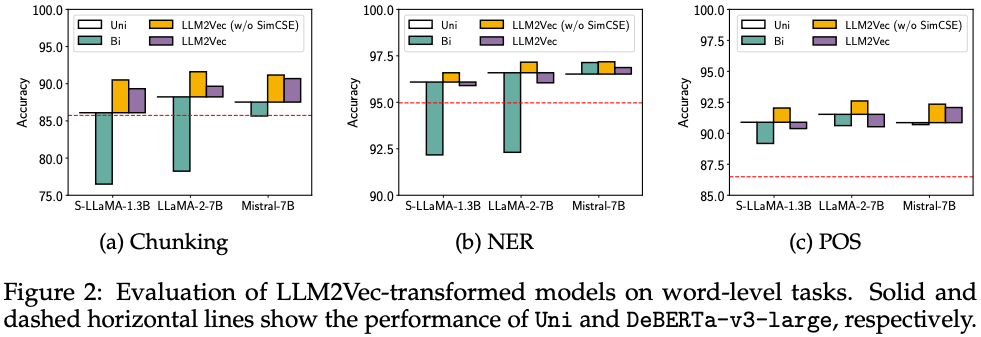
We evaluate on three word-level tasks: chunking, named-entity recognition (NER), and part-of-speech tagging (POS), using the CoNLL-2003 benchmark (Tjong Kim Sang & De Meulder, 2003).
- causal attention 사용한
Uni의 경우도 encoder baseline인 DeBERTa-v3-large보다 좋은 성능을 보임.
MNTP로 adaptation을 하지않은 경우, bidirectional attention의 성능이 떨어지는 것을 볼 수 있음.
- word-level tasks의 경우,
SimCSE를 적용하지 않은 경우가 훨씬 좋은 모습을 보임.
Evaluation on sequence-level tasks
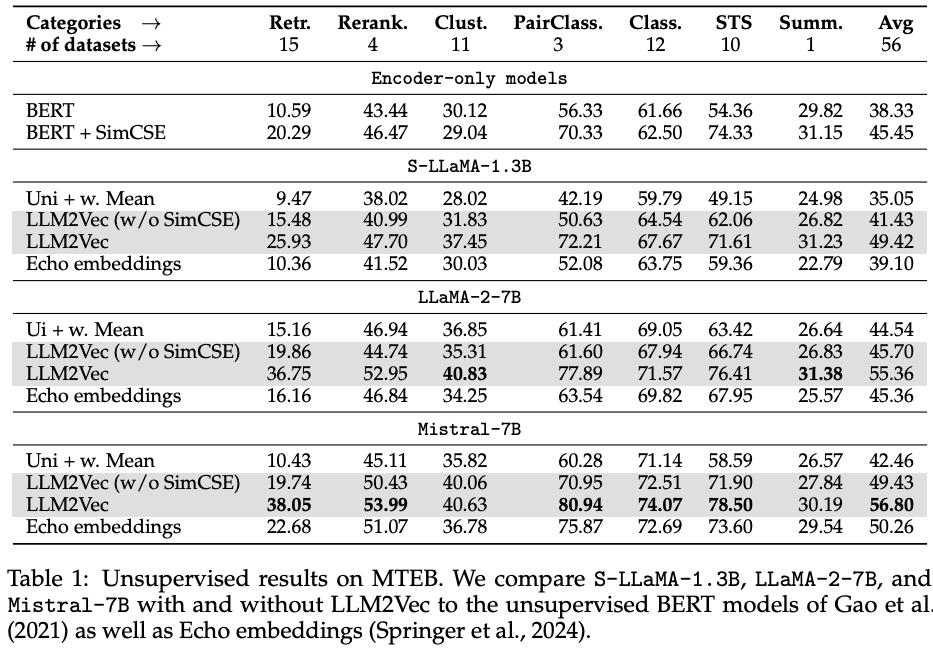
- Massive Text Embedding Benchmark (
MTEB)을 활용해서, sequence-leval tasks에 대한 성능을 측정함.
- 이전 연구인 “Improving text embeddings with large language models”를 따라서, task-specific instruction을 수행함.
- 이전 연구와 같은 instruction set을 사용하고, query에만 이를 붙임.
mean pooling 시, instruction tokens들은 제외함.
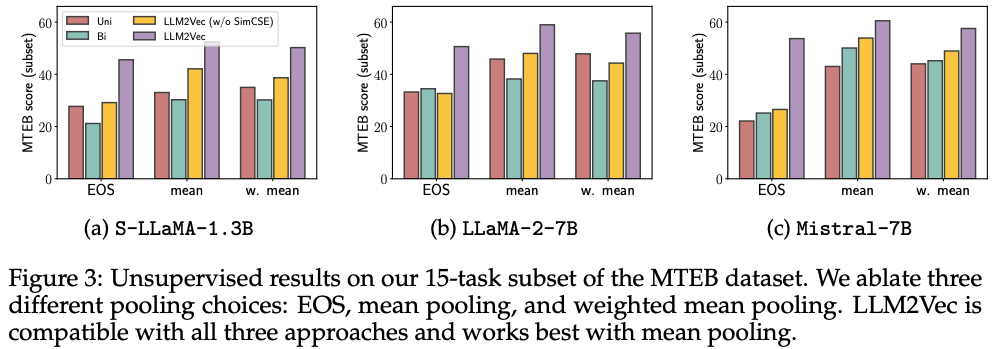
- sequence-level embedding을 얻기위해서, last EOS token의 embedding을 사용하는 것이 좋은 전략이 아님을 알 수 있음.
- bidirectional attention을 adapt하지않고 적용하는 것은
Mistral-7B를 제외하고 문제였음.
MNTP와 SimCSE를 적용하는 것이 성능을 증대시킴.
- 공정한 비교를 위해서,
LLM2Vec 방법에서 MNTP까지만 적용한 뒤, Echo embedding과 비교해보면 거의 비슷한 성능을보임. 그러나 Echo embedding 대비 아래의 이득이 있음.However, compared to Echo embeddings, LLM2Vec is much more efficient as Echo embeddings repeat the input and therefore double the sequence length which makes inference considerably slower (we provide a runtime comparison in Appendix E.2).
How does LLM2Vec affect a model?
LLM2Vec helps models to capture information from future tokens
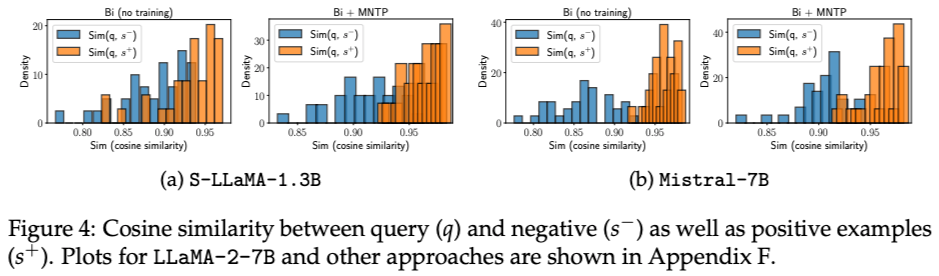
Echo embedding 연구에서 사용했던 방법과 데이터를 동일하게 사용하여, future tokens로부터 information을 얼마나 capture하는 지 평가how good models are at judging the similarity of sentences that have different meanings but share the same prefix.
Echo embedding 연구에서 데이터는 아래와 같이 구성됨.- 35 sentence triples {(qi,si+,si−)}i=135
- qi=(Ai,Bi), si+=(Ai,Ci), si−=(Ai,Di)
- Bi와 Ci는 서로 비슷한 의미, Di는 다름.
- 위와 같은 데이터 구성에서 shared prefix에 해당하는 Ai가 future tokens의 정보를 얼마나 잘 반영하는 지 분석함.
A model that incorporates information from future tokens (Bi,Ci,or Di) in the representations of the prefix Ai should assign a higher similarity to the positive example.
S-LLaMA-1.3B의 경우는 MNTP까지 적용해야, positive와 negative를 잘 구분하는 반면에, Mistral-7B의 경우는 MNTP로 bidirectional attention에 adapt하지 않아도 잘 구분하는 모습을 보임.
Why does bidirectional attention without training work for Mistral models?
Mistral-7B가 MNTP로 bidirectional attention에 adaptation을 시키지 않아도 잘 동작하는 이유를 분석하기위한 시도를 함.
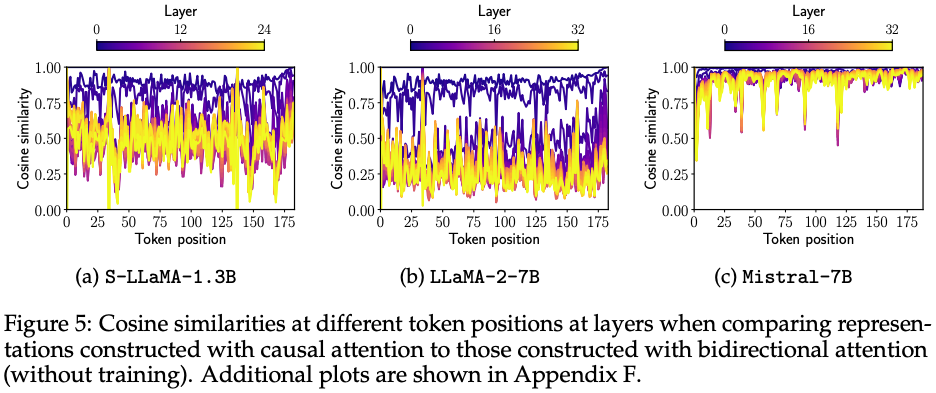
- wikipedia의 paragraph를
Mistral-7B로 추론을 해서, sim(Hlc,Hlbi)의 similarity를 계산함. → bidirectional attention을 adaptation 없이 사용 하는 경우, similarity 값이 작을 것이라고 생각함.- Hlc: the hidden representations of every token at ever layer l with causal attention
- Hlbi: the hidden representations of every token at ever layer l with bidirectional attention
S-LLaMA-1.3B, LLaMA-2-7B는 예상과 같았으나 Mistral-7B는 그러지 않았음.we speculate that Mistral models are pre-trained with some form bidirectional attention, e.g., prefix language modeling (Raffel et al., 2020) – at least for some parts of its training.
Combining LLM2Vec with supervised contrastive learning
LLM2Vec leads to strong performance on the MTEB leaderboard
- supervised contrastive learning을 위해서
E5 dataset에서 공개가 되어 사용할 수 있는 부분만 사용함.
- 일반적인 contrastive learning 방식을 따름.
We follow standard practice and train the models with contrastive learning using hard negatives and in-batch negatives.
LoRA를 아래와 같은 방식으로 사용함.The MNTP LoRA weights are merged into the base model, and the trainable LoRA weights are initialized with SimCSE weights. For LLM2Vec models that use just MNTP, the LoRA weights are randomly initialized. The training is performed for 1000 steps with a batch size of 512.
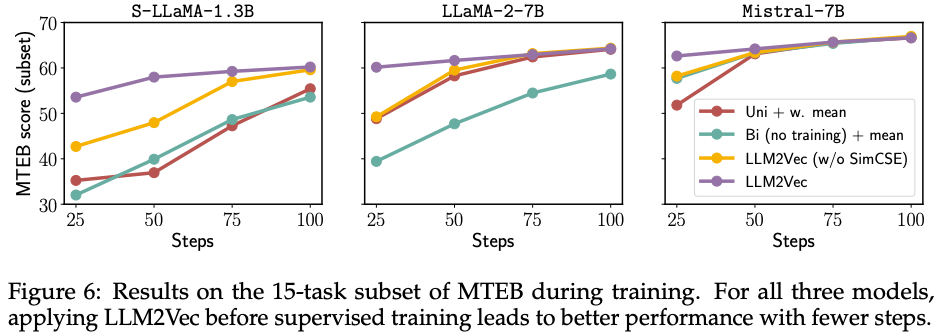
- supervised contrastive learning에서
SimCSE는 덜 중요해지는 것 처럼 보이지만, sample-efficient training을 할 수 있게 해주는 trick으로써 작용함.As shown in Figure 6, LLM2Vec-transformed models achieve better performance earlier in training. This observation is consistent across all three models. For S LLaMA-1.3B, the smallest of our three models, even performing just MNTP leads to considerably improved sample efficiency. These results are particularly encouraging for settings where it is hard to acquire high quality labeled data, a setting which we leave for future work.