Technical Specifications
Architecture
- image와 textual prompt를 input으로 받고, output으로 text를 주는 multimodal model
This model is composed of two primary components: an image encoder, i.e., CLIP ViT-L/14 [RKH+21] and a transformer decoder, i.e., phi-3-mini-128K-instruct.
- high-resolution image와 various aspect ratios를 처리하기위하여, dynamic cropping strategy를 사용함.
Pre-training
- next token prediction의 loss로 학습, image token에서 발생하는 loss는 사용하지않음.
The pre-training process involves a total of 0.5T tokens that encompass both visual and text elements. During the pre-training phase, the maximum image resolution is capped at 1344 ×1344 as the majority of the training images are smaller than this resolution.
Post-training
- sft와 dpo 두 가지 stage로 구성됨.
- 각각 text-only와 multimodal 두 가지 type으로 구성함.
- 각 stage마다 두 type을 jointly training을 함.
For these two stages, we jointly train multimodal tasks and text only tasks so that the model can achieve multi-modal reasoning while maintaining language capabilities
as much as possible.
Academic benchmarks
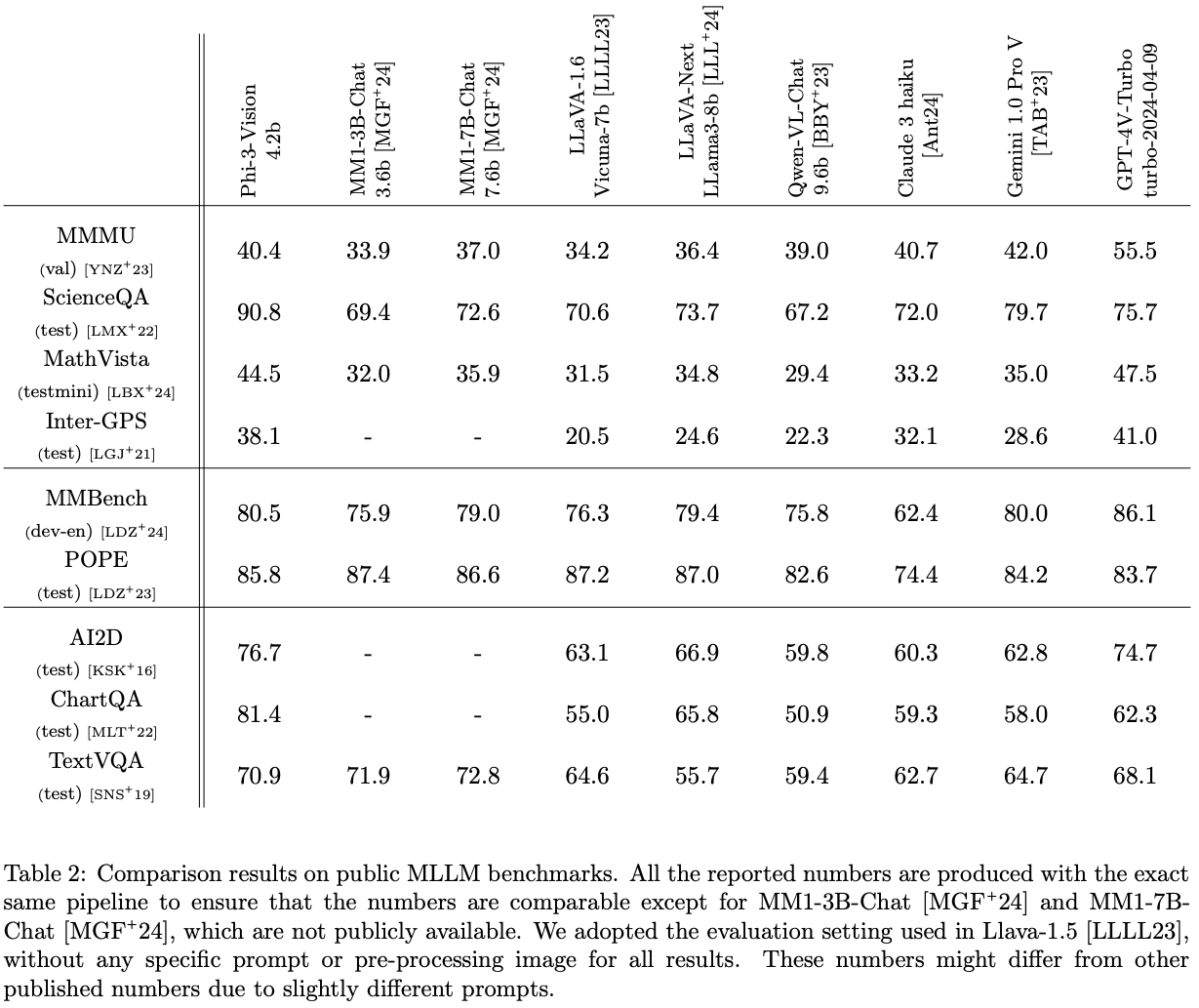
Llava-1.5의 evaluation setting을 따라서 평가
Safety & Weakness
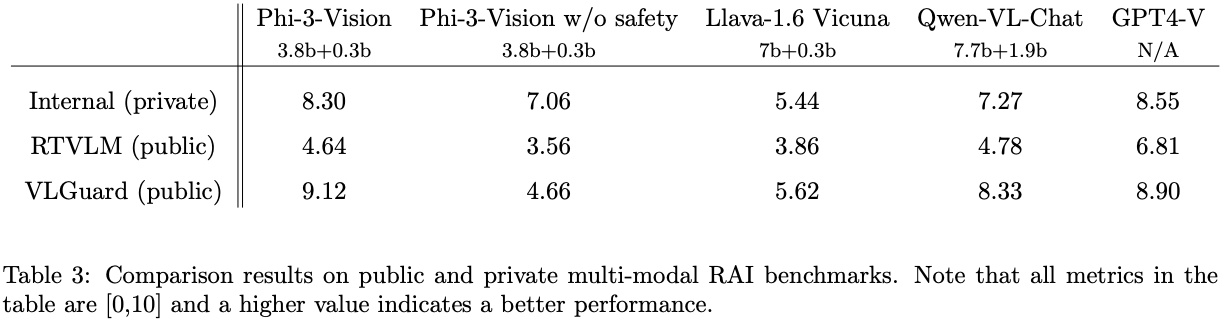
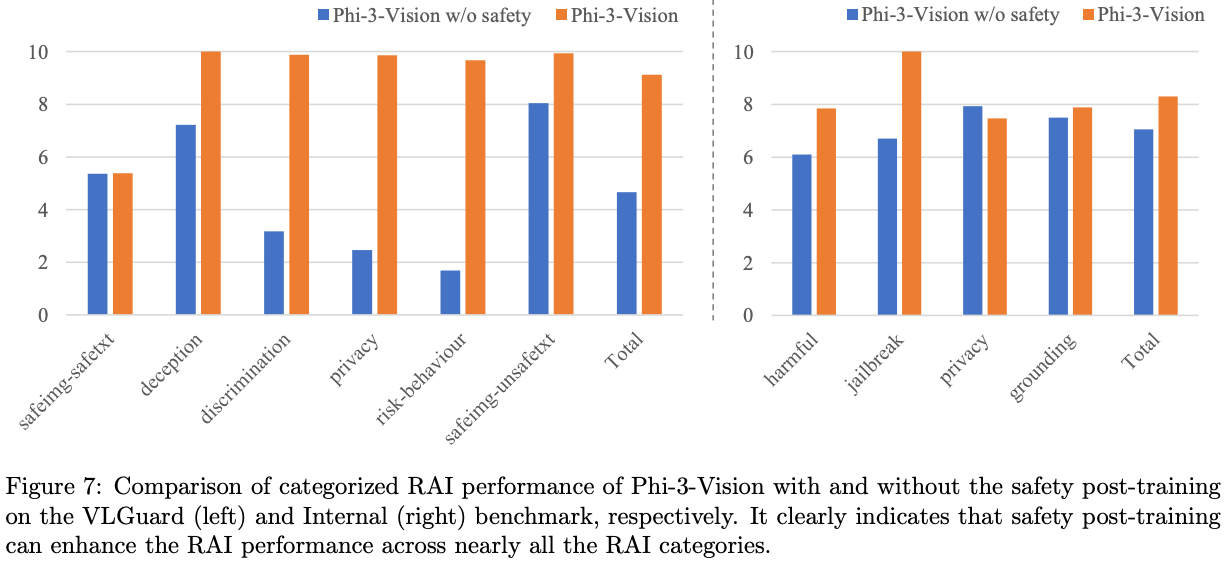
- safety를 위한 post-training도 sft, dpo로 두 stage로 진행함.
phi-3-vision의 경우도phi-3-mini를 decoder로 사용했기 때문에,phi-3-mini와 비슷한 문제가 발생함을 확인함.However, we have identified certain limitations, particularly with questions necessitating high-level reasoning abilities. Additionally, the model has been observed to occasionally generate ungrounded outputs, making it potentially unreliable in sensitive areas, such as finance. To mitigate these issues, we will incorporate more reasoning-focused and hallucination-related DPO data into post-training in the future.