Abstract
- web에서 얻은
textbook qualitydata (6B tokens)과 GPT-3.5로 만든generated textbooks and exercises(1B tokens)로 1.3B scale의phi-1을 학습시킴.
- 1.3B라는 다소 작은 scale에도 불구
HumanEval과MBPP에서 높은 성능을 기록함.Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP.
Introduction
- TinyStories 연구에서 data quality가 올라가면 기존의 우리가 익숙한 scaling law (e.g. chinchilla scaling law)보다 훨씬 효율적인 scaling law를 얻을 수 있음을 보임.
- 위 연구에서는 data quality를 올리기위한 방법으로 synthetic dataset을 생성하는 방법을 취함.
- TinyStories가 언어로서 english를 가르치기위한 dataset에 집중했다면, 본 연구에서는 code에 집중함.
- 정확히는 docstring이 주어졌을 때 그로부터 python function 작성하는 방법을 학습시키는 것에 집중함.
- 이를 위해 두 가지 dataset을 만들고 1.3B model 학습에 활용함.
- 이를 통해 기존의 scaling law보다 훨씬 좋은 scaling law로 좋은 모델을 학습함.
Training details and the importance of high-quality data
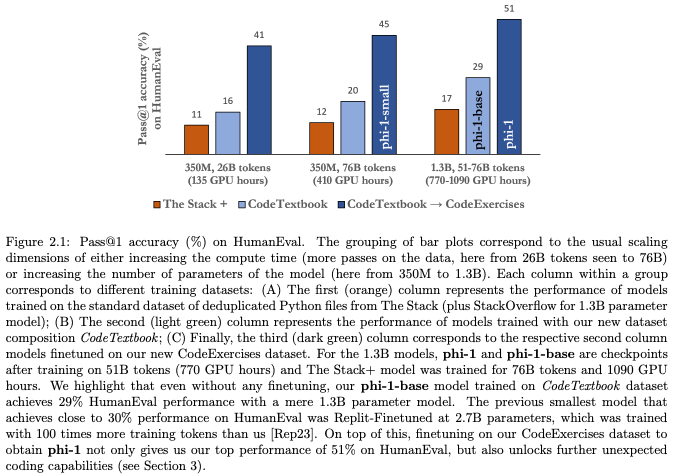
- 기존에 code를 학습하기위한 dataset (e.g. TheStack)은 textbook처럼 self-contained, instructive, balanced하지않음. → optimal하지않음.
One can only imagine how frustrating and inefficient it would be for a human learner to try to acquire coding skills from these datasets, as they would have to deal with a lot of noise, ambiguity, and incompleteness in the data.
drawbacks (quotation)
- textbook 처럼 clear, self-contained, instructive, balanced된 dataset은 high-quality data라고 볼 수 있고, 사람이 textbook으로 무언가를 배우듯이 model도 textbook like한 high-quality data로 학습하면 더 좋은 성능을 낼 수 있을 것임.
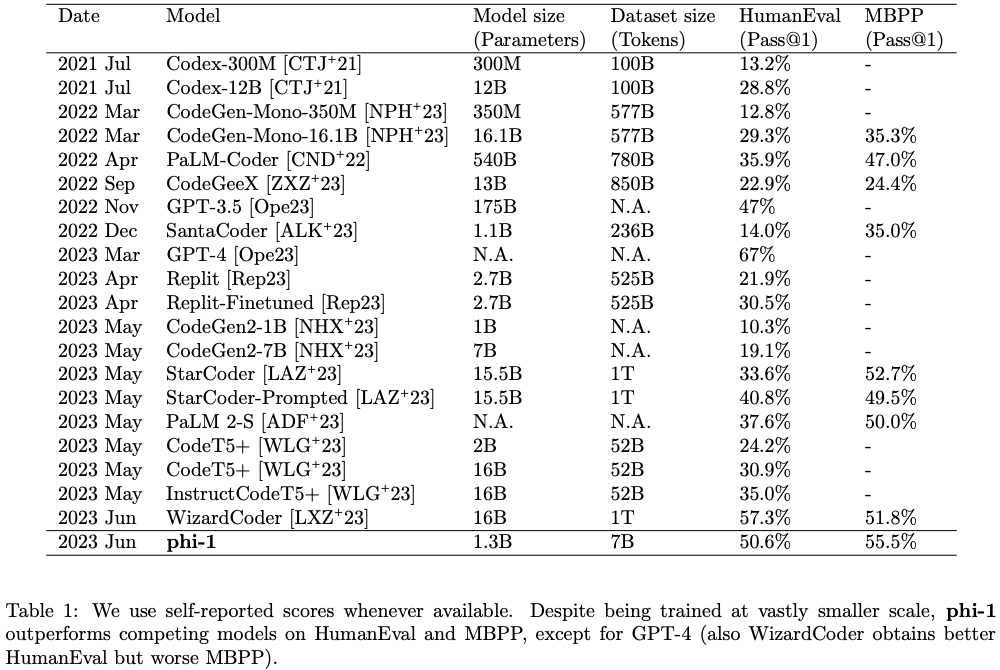
CodeTextbook으로 학습한phi-1-base의 경우, 비교군인TheStack+으로 학습한 경우보다,HumanEval에서 확실히 개선되는 모습을 보임.
phi-1-base를CodeExercises로 추가학습한phi-1의 경우,CodeExercises의 양이 적음에도 불구하고,HumanEval성능을 대폭 상승시키고,phi-1-base에 없었던 새로운 ability를 unlocking함.Despite the small size of the “CodeExercises” dataset, finetuning with this dataset is crucial not only for large improvements in generating simple Python function as shown in Figure 2.1, but more broadly to unlock many interesting emergent capabilities in our phi-1 model that are not observed in phi-1-base (see Section 3).
→ 이 후 CodeTextbook과 CodeExercises를 어떻게 만들었는 지 아래 섹션에서 다룸.
Filtering of existing code datasets using a transformer-based classifier
CodeTextbook의 subset인 filtered code-language dataset을 만들기위하여 아래와 같은 과정을 거침.
- deduplicated된 TheStack과 StackOverflow의 35B tokens로 부터시작
- 위의 dataset에서 sampling을하여 subset을 구성, 해당 subset을 GPT-4를 이용하여, 어떤 instance가 textbook-quality에 가까운 지 labeling
the model is prompted to “determine its educational value for a student
whose goal is to learn basic coding concepts”.
- labeling된 데이터로 random forest classifier를 학습하여 사용함.
We then use this annotated dataset to train a random forest classifier that predicts the quality of a file/sample using its output embedding from a pretrained codegen model as features.
Creation of synthetic textbook-quality datasets
CodeTextbook의 subset인 synthetic textbook dataset을 만들 때, diversity를 확보하는 것에 주력함.
- dataset의 diversity는 해당 dataset을 학습하는 model의 generalization을 의미하게됨.
- code generation과 관련된 diversity는 아래와 같이 생각해볼 수 있음.
By diversity, we mean that the examples should cover a wide range of coding concepts, skills, and scenarios, and that they should vary in their level of difficulty, complexity, and style.
- diversity를 확보하기위해서 TinyStories 연구과 유사한 방식으로 generation을 함.
we look for ways to inject randomness into the prompt in a way that gives rise to the generation of a diverse dataset.
synthetic textbook datasetsynthetic exercises dataset


Model architecture and training
phi-1-small | phi-1-base, phi-1 | |
| num_hidden_layers | 20 | 24 |
| num_attention_heads | 16 | 32 |
| hidden_size | 1024 | 2048 |
| intermediate_size | 4096 | 8192 |
| layer pattern | parallel | parallel |
| attention type | MHA | MHA |
| mlp activation type | gelu | gelu |
| position embedding | RoPE | RoPE |
| max_position_embeddings | 2048 | 2048 |
| tie_word_embeddings | False | False |
| tokenizer | codegen-350M-mono | codegen-350M-mono |
- pretraining
CodeTextbook(textbook-quality data, ~7B)을 8 epoch 정도 (> 50 tokens)를 돌려서 학습함. →phi-1-base
- finetuning
CodeExercises(textbook-exercise-like data, ~180M)으로phi-1-base를 학습 →phi-1
Spikes of model capability after finetuning on CodeExercises
phi-1-base를 CodeExercises로 finetuning한 phi-1에서 CodeExercise에 없는 문제도 잘 풀어냄을 확인함.
CodeExercises는 기본 python library만을 이용하여 coding을 하는 데이터들임.
phi-1은CodeExercises로 학습했음에도 불구하고, 복잡한 알고리즘을 풀어내거나 external python library도 사용하는 코드를 작성할 수 있었음.This suggests that our finetuning process might have helped the model in reorganizing and consolidating the knowledge acquired during pretraining, even if such knowledge is not explicitly present in our CodeExercises dataset.
Finetuning improves the model’s understanding
phi-1이 phi-1-base 대비 logical relationship을 더 잘 이해하는 모습을 보임.

Finetuning improves the model’s ability to use external libraries
finetuning에 사용한 CodeExercises에 external python library를 사용하는 문제를 target하지 않음에도, phi-1이 external python library를 사용하는 task를 잘하게됨을 볼 수 있고, 심지어 chat도 잘하게됨을 확인할 수 있음.

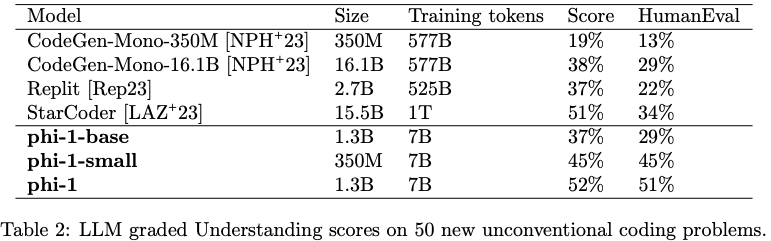
Evaluation on unconventional problems with LLM grading
HumanEval에 대해서 CodeExercises가 contamination 우려가 있어, 새롭게 benchmark를 만들어서 평가를 진행함.
HumanEval과 비슷한 format이지만, 실제로 없을만한 문제들을 제작함.example

- GPT-4를 이용하여 평가,
HumanEval에서 보인 다른 model들과의 비교 성능 순위를 동일하게보여줌.
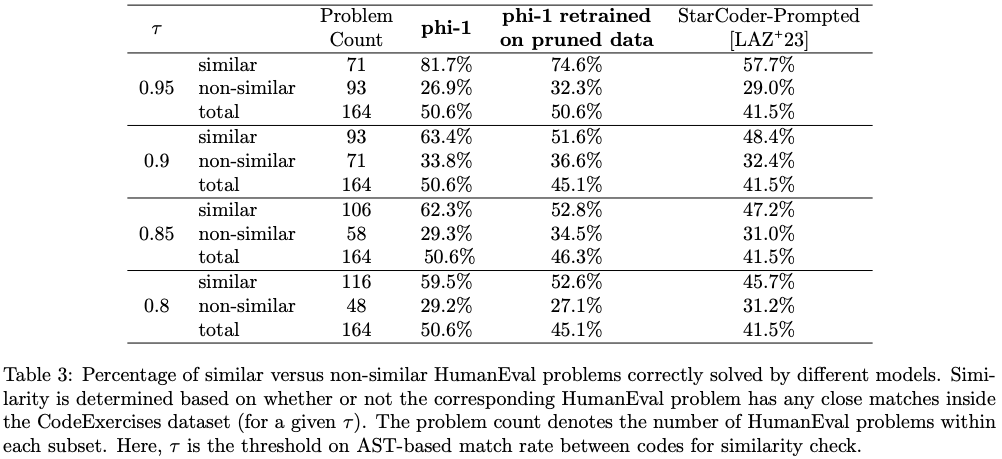
Data pruning for unbiased performance evaluation
HumanEval과 유사한 CodeExercises example을 제거한 pruned dataset으로 phi-1을 학습하고, 이에 따른 성능 추이를 확인함.
- 를 0.95 → 0.8로 변경함에 따라, 879.5K의 example로 구성된
CodeExercises에서 42.5K에서 354개의 example을 제거함.
- 성능이 어느정도 유지됨으로 보아서, contamination 때문에 점수가 높았던 것이 아님을 알 수 있음.
Conclusion
our work demonstrates the remarkable impact of high-quality data in honing a language model’s proficiency in code-generation tasks. By crafting “textbook quality” data we were able to train a model that surpasses almost all open-source models on coding benchmarks such as HumanEval and MBPP despite being 10x smaller in model size and 100x smaller in dataset size. We hypothesize that such high quality data dramatically improves the learning efficiency of language models for code as they provide clear, self-contained, instructive, and balanced examples of coding concepts and skills.