Abstract
phi-1이 특히 python code generation에 특화해서 학습했다면,phi-1.5에서는 동일한 approach (synthetic dataset 생성)로 natural language에 있는 common sense를 학습하는 데에 초점을 둠. → natural language tasks의 성능이 기존phi-1보다 훨씬 증대됨.
phi-1.5는 기존phi-1과 같이 1.3B라는 scale에도 불구하고, LLMs 가진 특징들이 나타났으며 일반적인 web data를 사용하지않아, toxic & biased generation에서 훨씬 나은 모습을 보여줌.phi-1.5 exhibits many of the traits of much larger LLMs, both good –such as the ability to “think step by step” or perform some rudimentary in-context learning– and bad, including hallucinations and the potential for toxic and biased generations –encouragingly though, we are seeing improvement on that front thanks to the absence of web data.
Introduction

phi-1.5에서는 이전 연구들인tinystories,phi-1을 더욱 확장하여, larger scale의 LLM이 가지고 있는 capability를 small scale의 sLLM으로 얻어낼 수 있는 지, 없는 지에 대해 집중함.In this work we continue the investigation into the fundamental question of “how small can a LLM be to achieve certain capabilities”. The prior work [EL23] considered this question for the task of “speaking fluent English”, while the subsequent work [GZA+23] considered the more challenging task of coding simple functions in Python. Here we focus on the more elusive concept of common sense reasoning, a notoriously challenging task for AI [SBBC21].
- 이전 연구인
phi-1에서 7B tokens로 dataset을 구성했던 것 대비,phi-1.5는 common sense를 학습하기위한 synthetic dataset을 생성하여, 새로이 30B tokens로 dataset을 구축함.phi-1.5를 학습하기위한 dataset에filtered web-dataset추가해, (phi-1에서filtered code-language dataset의 대응물), 새로운 dataset 구성으로phi-1.5-web을 학습하여,filtered web-dataset의 가치도 증명함.
phi-1.5에서 larger scale의 LLM이 가지는 특징들이 나타내는 것을 확인함.
Technical specifications
Architecture
phi-1과 동일한 구조를 채택함.
phi-1-small | phi-1-base, phi-1 | phi-1.5 | |
| num_hidden_layers | 20 | 24 | 24 |
| num_attention_heads | 16 | 32 | 32 |
| hidden_size | 1024 | 2048 | 2048 |
| intermediate_size | 4096 | 8192 | 8192 |
| layer pattern | parallel | parallel | parallel |
| attention type | MHA | MHA | MHA |
| mlp activation type | gelu | gelu | gelu |
| position embedding | RoPE | RoPE | RoPE |
| max_position_embeddings | 2048 | 2048 | 2048 |
| tie_word_embeddings | False | False | False |
| tokenizer | codegen-350M-mono | codegen-350M-mono | codegen-350M-mono |
Training data
- 기존
phi-1의 대략 7B tokens로 구성된 dataset (CodeTextbook,CodeExercises)을 포함.
- 위의 사항에 더해서, common-sense와 general knowledge (science, daily activities, theory of mind, etc.)등을 가르치기위한
GeneralTextbook(textbook-quality data, ~20B)를 생성함.
- 따라서 전체 데이터셋 구성에서
CodeTextbook을 일부인filtered code-language dataset(6B)만 non-synthetic part임.
Training details

- dataset의 중요성을 강조하기위해서, warmup을 사용하지않고, constant learning rate로 2e-4를 사용함.
- mixed precision training으로 fp16을 사용하고, 더불어지 DeepSpeed ZeRO stage 2를 사용함.
- batch size 2048로, 대략 5 epoch (~150B)학습함.
- dataset 관점에서는 multi-epoch
- 실제 데이터 비중은
phi-1을 구성하는 dataset (주로 code) 20% (~30B),phi-1.5를 만들기위해 새로 모은 dataset (주로 common-sense와 general knowledge)가 80% (~120B) 정도가됨.
Filtered web data
web dataset의 중요성과 영향도를 파악하기위해서, filtered web-dataset (~95B)를 구축하여, 아래와 같은 모델을 추가적으로 학습하고, phi-1.5와 비교함.
filtered web-dataset- web
- Falcon refined web dataset에서
phi-1.0에서 사용한 filtering 기법을 활용하여, 88B tokens를 확보함.
- Falcon refined web dataset에서
- code
- TheStack과 StackOverflow를 filtering하여 7B tokens를 확보함.
- web
filtered web-dataset을 활용한 model은 아래와 같음.
phi-1.5-web-onlyfiltered web-dataset의 web과 code 파트를 각각 80%, 20%의 비중으로 학습함.
phi-1.5-web(Data size: ~100B, Train tokens: ~300B)filtered web-dataset,CodeTextbook&CodeExercises,GeneralTextbook을 40% (~120B), 20% (~60B), 40% (~120B)의 비중으로 학습함.
학습한 phi-1.5-web-only, phi-1.5, phi-1.5-web은 불완전하게나마 instruction을 following하는 능력이 있었음.
Nevertheless, they can be prompted to follow instructions in a question-answering formats, but not perfectly
Benchmark results

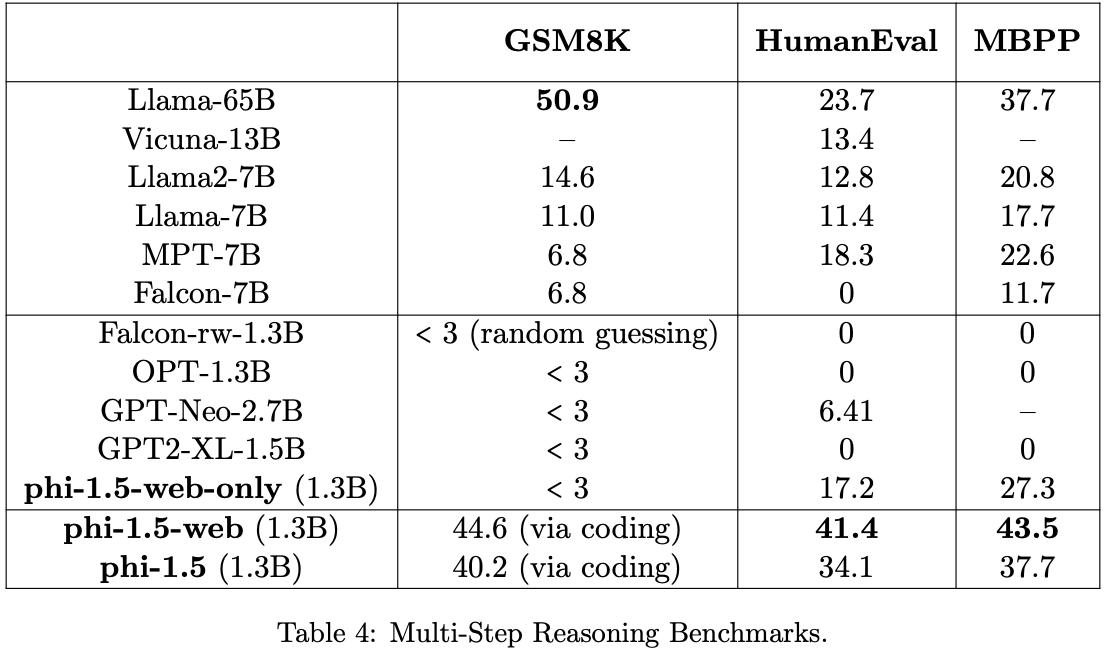
전체적으로 coding only만 학습한 phi-1 (pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. ) 대비, code점수가 크게 떨어지지는 않으면서도 code task가 아닌 common-sense reasoning 또는 language understanding task에서 점수가 좋아서, 이를 바탕으로 아래를 주장함.
Interestingly we can see that phi-1.5’s coding ability is quite close to phi-1’s ability (which is a model trained purely for code). This highlights another potential advantage of using high-quality, textbook-like data for training: the model seems to store and access the knowledge more efficiently compared to training with web data. Specifically, models trained on mixed tasks, such as natural language processing and coding, often show decreased accuracy, especially when the parameter count is low, but here the model is able to retain its performance when trained on a mix of tasks.
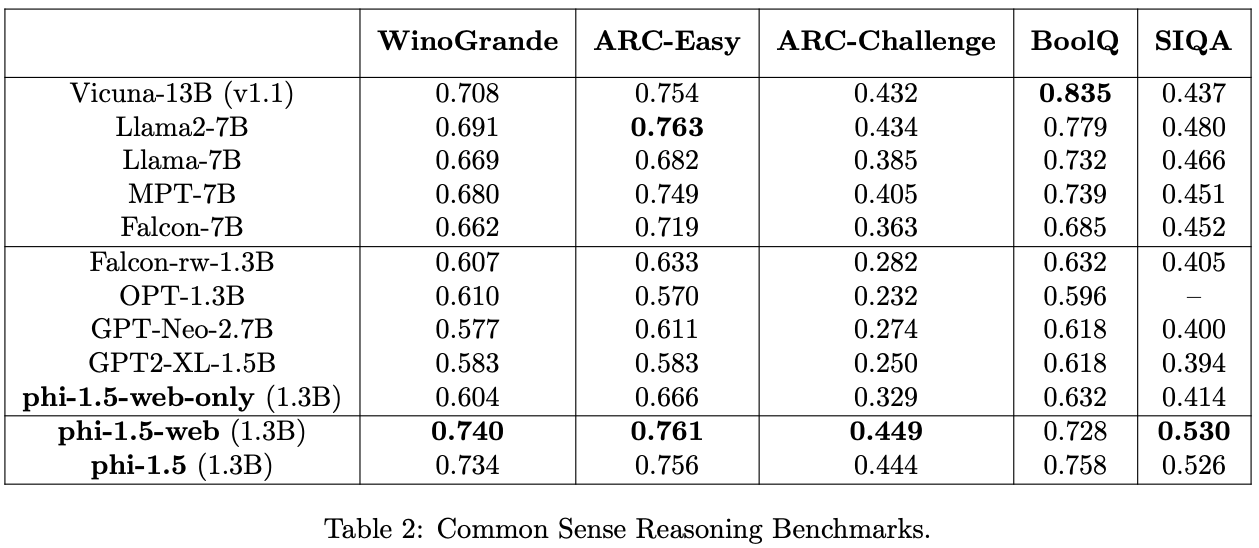
common-sense reasoning
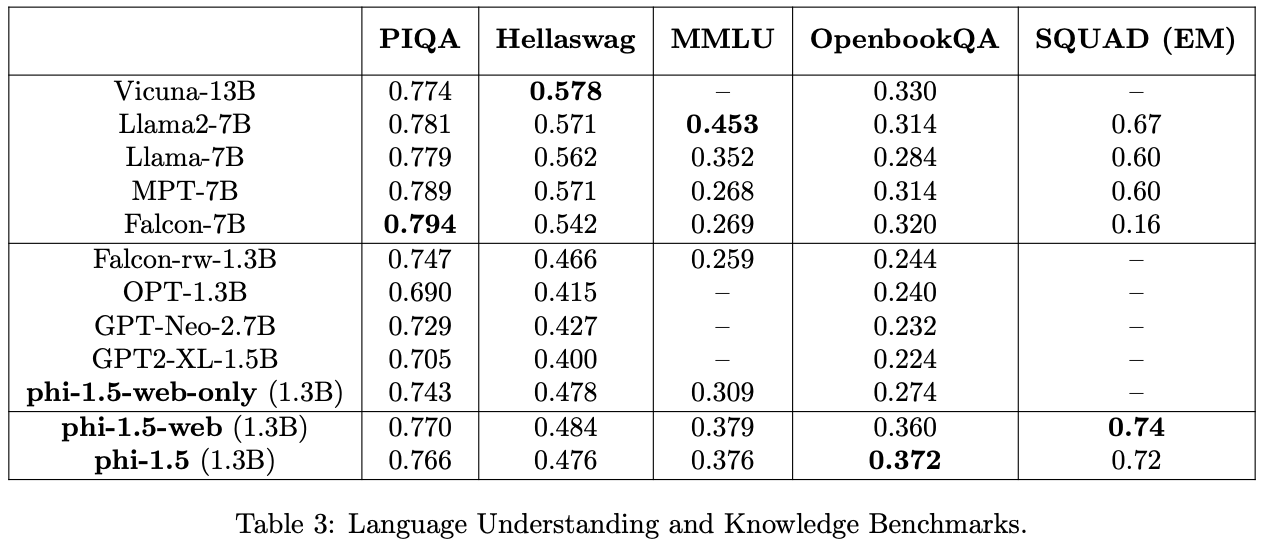
language understanding
reasoning abilities (through mathematics and coding)
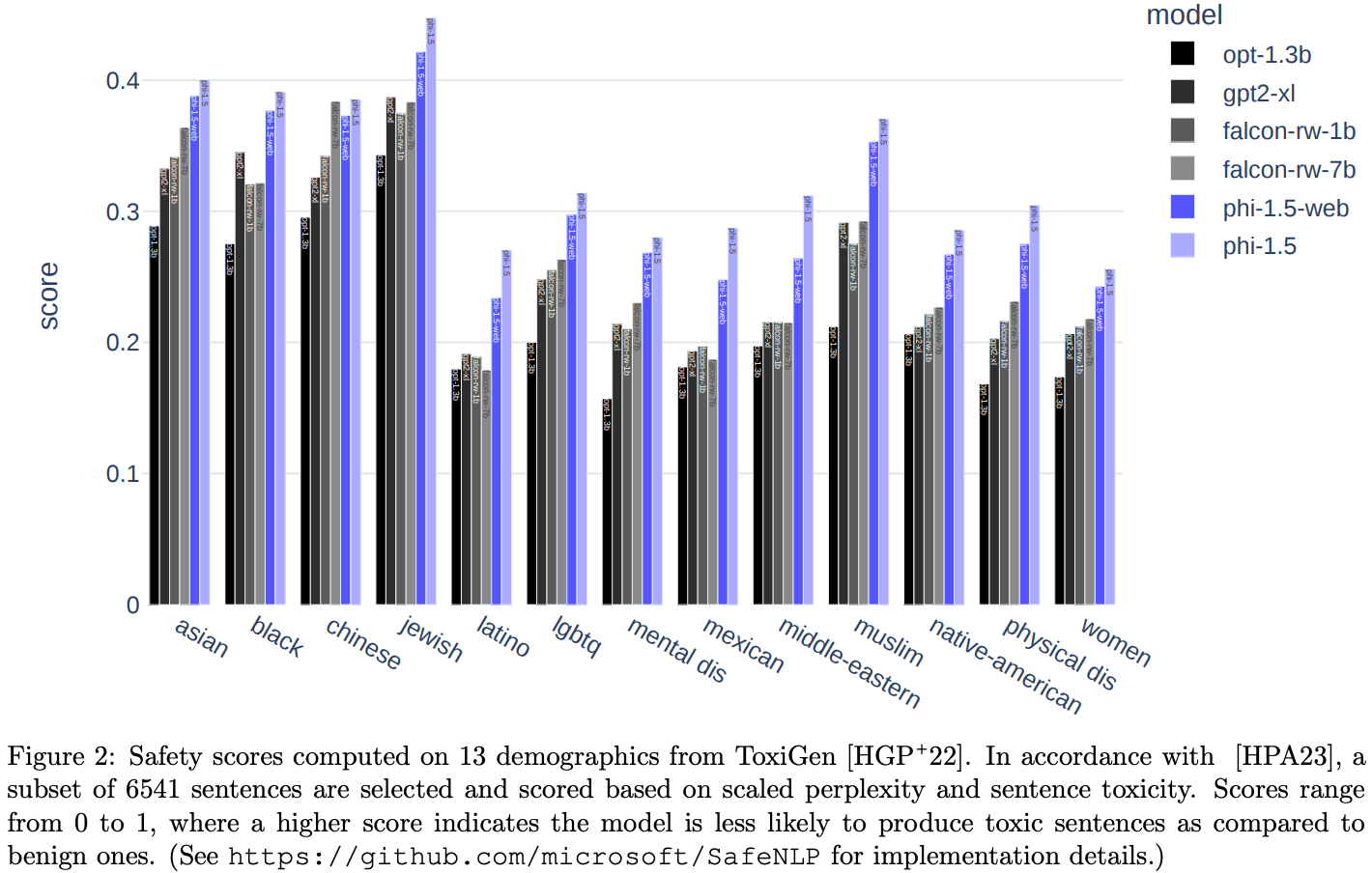
Addressing Toxicity and Biases
phi-1.5, phi-1.5-web이 다른 비교 대상들 대비 toxic content generation 측면에서 나았음.
phi-1.5를 통해서 textbook-like synthetic data를 사용하는 것이, toxic cotent generatin을 덜하게함을 알 수 있음.
phi-1.5-web을 통해서, textbook-like한 web dataset을 filtering을 통해서 얻어내는 것이 역시 중요함을 알 수 있음.
Usage of our model
phi-1.5,phi-1.5-web의 경우 alignment를 위한 노력 (e.g. instruction-based finetuning, rlhf) 등을 하지 않았음에도, 어느정도 instruction을 따르거나 chat을 할 수 있는 기본적인 능력이 있음.
- 이는 synthetically generate textbook에서 발견된 “exercises and answers`가 일종의 instruction-based finetuning에 사용되는 dataset과 비슷한 역할을 해서일 것이라고 생각함.
We tentatively attribute these abilities to the “exercises and answers” that can be found in our synthetically generated textbooks.
아래는 예시
Direct completion



Question and answer


Chat mode
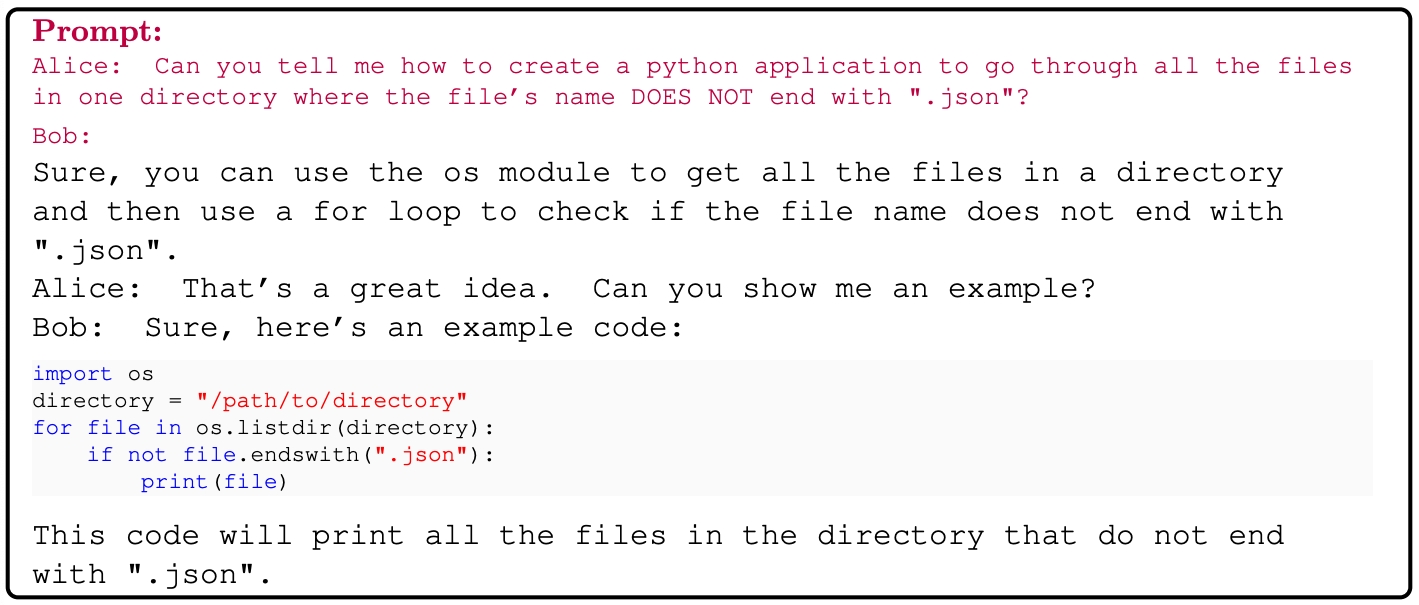

Python coding

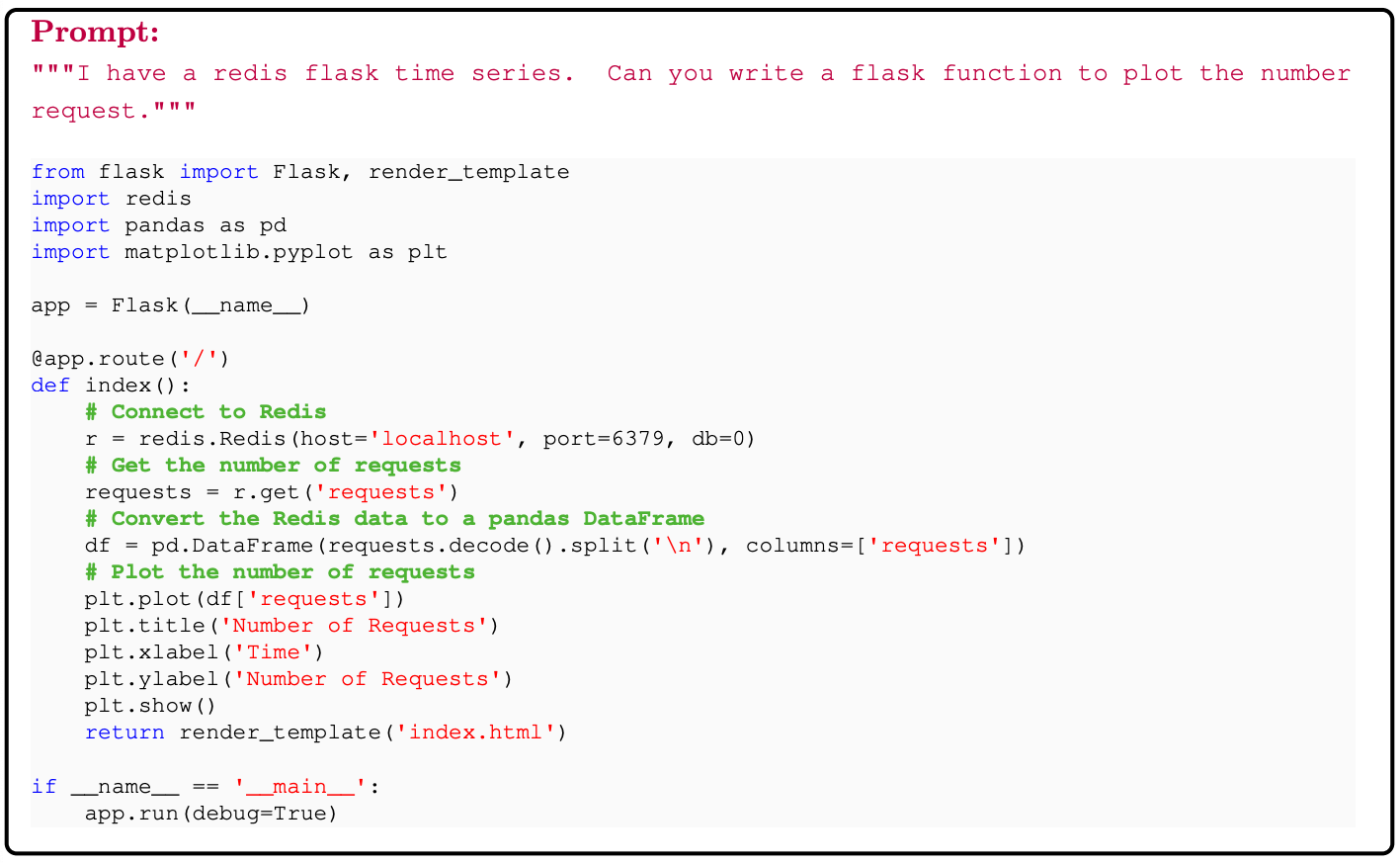
Discussion
We introduced phi-1.5, a 1.3 billion parameter LLM, trained primarily on a specially curated “textbook-quality” synthetic dataset. Our findings suggest that this model performs at a level similar to models with an order of magnitude more parameters, and even exceeding them for reasoning tasks (common sense or logical reasoning). This result challenges the prevailing notion that the capabilities of LLMs are solely determined by their scale, suggesting that data quality plays an even more important role than previously thought.