Abstract
NV-Embed라는 LLM decoder를 embedding을 뽑기위한 model로 변환하는 방법을 제안함.
latent attention layer라는 좋은 embedding을 얻기위한 pooling 방법을 제안함.
- 좋은 embedding을 얻기위해 representation learning을 개선하는 방법으로, contrastive learning 과정에서 causal attention masking의 제한을 풀어버리는 방식을 취함.
- 위의 contrastive learning은 두 가지 stage로 구성
Introduction & Related Work
LLM을 RAG 방식으로 활용하는 데에 있어서, embedding-based retriever가 매우 중요해지고 있고, 근래 decoder-only LLMs로 embedding을 구하는 방식의 성능이 높은 수준에 이름.
The most recent work by Wang et al. (2023b) demonstrates that decoder-only LLMs can outperform frontier bidirectional embedding models (Wang et al., 2022; Ni et al., 2021; Chen et al., 2023) in retrieval and general-purpose embedding tasks.
NV-Embed는 과거의 관련 연구들보다 좀 더 simplicity와 reproducibility에 초점을 맞추어 연구되었고, 아래와 같은 기여를 함.
- 제안한 pooling technique인
latent attention layer가 기존의 pooling 방법론들 보다 좋음을 보임.In contrast to the popular average pooling in bidirectional embedding models (e.g., Wang et al., 2022) and the last <EOS> token embedding in decoder-only LLMs (Neelakantan et al., 2022; Wang et al., 2023b)
- 기존 decoder only LLMs는 causal attention mask를 이용해서 학습이 되었고, 과거 연구들은 이를 bidirection으로 바꾸는 데, 여러 stage를 요함. →
NV-Embed에서는 이를 그냥 contrastive training 단계에 녹여내서 이를 단순화함.
two-stage contrastive instruction-tuning을 제안하고, 이를 이용하여Mistral-7B를 학습함. 이 방식으로 retrieval뿐만 아니라, embedding이 필요한 다른 task (e.g classification, clustering, semantic textual similarity tasks)에서도 좋은 성능을 냄을 확인함.In the first stage, we apply contrastive training with instructions on retrieval datasets, utilizing in-batch negative and curated hard negative examples. In the second stage, we blend carefully curated non-retrieval datasets into the stage-one training data. Since in-batch negative samples may be misleading for non-retrieval tasks, we disable in-batch negative training in stage two.
- 이 학습에서 다른 연구들과 달리 공개된 데이터셋만을 사용하고, 이미 존재하는 다른 embedding을 위한 model로부터 시작하지 않음. → for reproducibility
- 또한 다른 연구대비 simplicity에 신경씀.
SFR-Embedding-Mistral uses task-homogeneous batching, which constructs batches consisting exclusively of samples from a single task. In contrast, our NV-Embed uses well-blended batches consisting samples from all tasks to avoid potential “zigzag” gradient updates, which leads to a new record high score on both full MTEB and retrieval tasks compared to SFR-Embedding-Mistral.
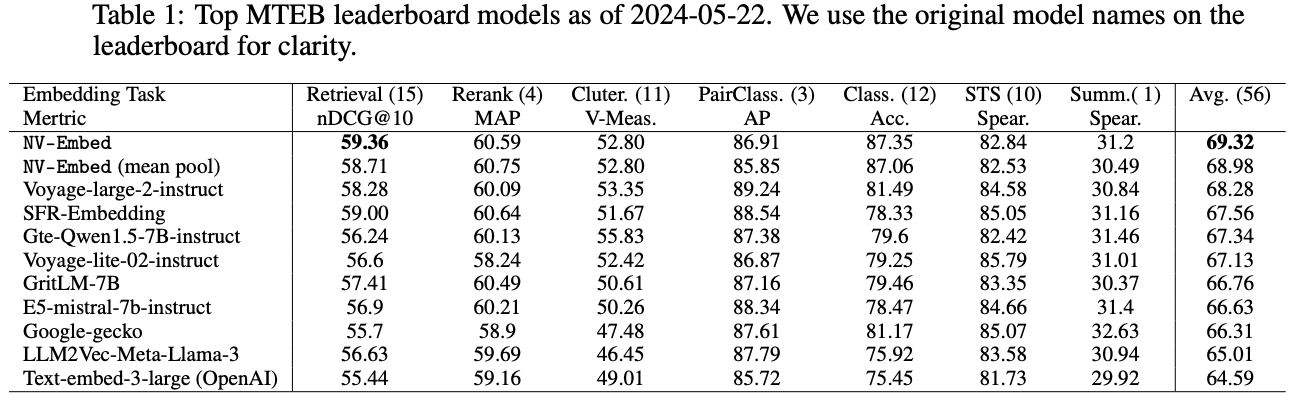
- 2024/05/22 기준으로 Massive Text Embedding Benchmark (a.k.a
MTEB)에서 SOTA
Method
Bidirectional Attention
- unidirectional attention은 model의 representation power를 제한함.
- 이전 연구들은 추가적인 training stage를 둬서 unidirectional attention → bidirectional attention으로 변화시킴.
In recent, LLM2Vec (BehnamGhader et al., 2024) introduces additional training phase with a specially designed masked token prediction to warm-up the bidirectional attention. GRIT (Muennighoff et al., 2024) utilizes a hybrid objective with both bidirectional representation learning and causal generative training.
NV-embed에서는 contrastive learning 단계에 이를 녹이면서 단순화함.
Latent Attention Layer
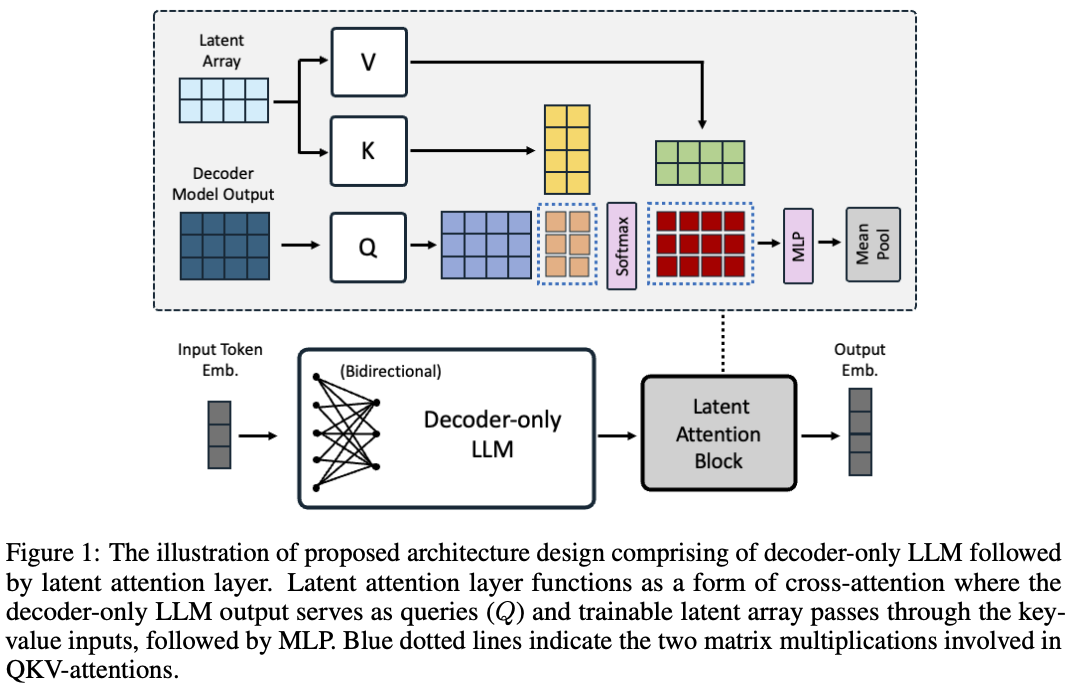
- bidirectional embedding models는 대부분 mean pooling을 사용하고, decoder-only LLM 기반의 embedding models는 “the last <EOS> token embedding”을 주로 사용함.
- mean pooling은 key phrases로부터 나온 중요정보가 희석된다는 단점이 존재함.
- “the last <EOS> token embedding”은 recency bias를 가지고있음.
- 이 문제를 해결하기위해
latent attention layer를 제안함.- cross-attention form으로 좋은 representation이라는 dictionary를 정의하는 형태로써의 학습을 시도함. (아래의 수식은 single head 기준으로 쓰여있음.)
- : the last layer hidden from decoder as Query, where is the length of sequence, and is the hidden dimension.
- : trainable “dictionary”, used to obtain better representation, where is the number of latents in the dictionary.
- : output of this cross attention
- cross attention의 output에 MLP를 태우고 mean pooling
which is followed by a regular MLP consists of two linear transformations with a GELU activation in between. Our model uses latent attention layer with r of 512 and the number of heads as 8 for multi-head attention. Finally, we apply mean pooling after MLP layers to obtain the embedding of whole sequences.
- cross-attention form으로 좋은 representation이라는 dictionary를 정의하는 형태로써의 학습을 시도함. (아래의 수식은 single head 기준으로 쓰여있음.)
Two-stage Instruction-Tuning
- 최근 연구는 task types과 different instruction에 맞는 output embedding을 얻기위해 instruction tuning이 retriever 학습과 embedding model 학습에 포함됨.
- 보통 retriever를 위한 embedding model학습에는 자주 사용되는 trick인
in-batch negatives가 매우 효율적이지만, 그 embedding model이 retrieval을 제외한 다른 task (e.g. classification, clustering)에는 부적합할 수 있음.
- 또한 일반적으로 retrieval task가 다른 task 대비 어려운 task, 따라서 retrieval task에 집중하는
two-stage instruction-tuning전략을 취함.which first conducts contrastive training with instructions on a variety of retrieval datasets (details are in section 4.1), utilizing in-batch negatives and curated hard-negative examples. In the second stage, we perform contrastive instruction-tuning on a combination of retrieval and non-retrieval datasets (details are in section 4.2) without applying the trick of in-batch negatives.
Training Data
- 공개 데이터셋만 사용하여 학습.
we exclusively employ public datasets to demonstrate our model’s capability in embedding tasks. Our training procedure incorporates both retrieval and non-retrieval tasks, including classification, clustering, and semantic textual similarity datasets.
- query-document pair가 주어져있을 때, training과 evaluation 모두 아래와 같은 형태로 template을 만들어서 활용함.
- latent attention layer의 마지막에서 mean pooling 시, instruction template에 해당되는 tokens는 pooling하지 않음.
template 예시사용 예시


Public Retrieval Datasets
- 아래와 같은 retrieval dataset들을 활용함.
We adopt the retrieval datasets as follows: MS MARCO (Bajaj et al., 2016), HotpotQA (Yang et al., 2018), Natural Question (Kwiatkowski et al., 2019), PAQ (Lewis et al., 2021), Stackexchange (StackExchange-Community, 2023), Natural language inference (Group et al., 2022), SQuAD (Rajpurkar et al., 2016), ArguAna (Wachsmuth et al., 2018), BioASQ (Tsatsaronis et al., 2015), FiQA (Maia et al., 2018), FEVER (Thorne et al., 2018).
- public retrieval dataset은 보통 hard negatives가 없으므로, hard negatives를 만들기 위해 아리를 수행함.
Typically, these datasets do not contain its own hardnegatives, necessitating the mining of such examples. To address this, we further finetune another encoder-based embedding model (Wang et al., 2022) to select the hardnegatives on those datasets
Public Non-retrieval Datasets
MTEB의 classification, clustering and semantic similarity (a.k. STS) 등의 train split을 활용함.
- retrieval dataset에 적용된 foramt을 동일하게 적용함. → contrastive loss를 사용한 contrastive training
- instructed query (containing query ), positive document , hard negative documents
- classification dataset은 아래와 같이 사용함.
We utilize the English training splits of various classification datasets from MTEB Huggingface datasets (Muennighoff et al., 2022; Lhoest et al., 2021). The classification datasets that we use are: AmazonReviews-Classification (McAuley & Leskovec, 2013), AmazonCounterfactualClassification (O’Neill et al., 2021), Banking77 Classification (Casanueva et al., 2020), EmotionClassification (Saravia et al., 2018), IMDB-Classification (Maas et al., 2011), MTOPIntentClassification (Li et al., 2021), ToxicConversations-Classification (Adams et al., 2019), TweetSentimentExtraction-Classification (Maggie, 2020).
- record에서
textfield를 로,label_textfield를 로 활용하고, 다른 record의label_text를 로 활용함.
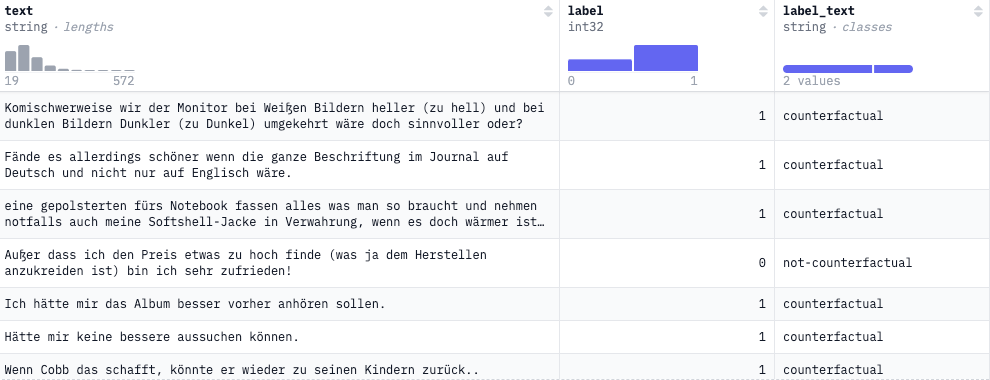
- 기준으로 stratified sampling을 수행하여 사용함.example: AmazonCounterfactualClassification
- record에서
- clustering dataset은 아래와 같이 사용함.
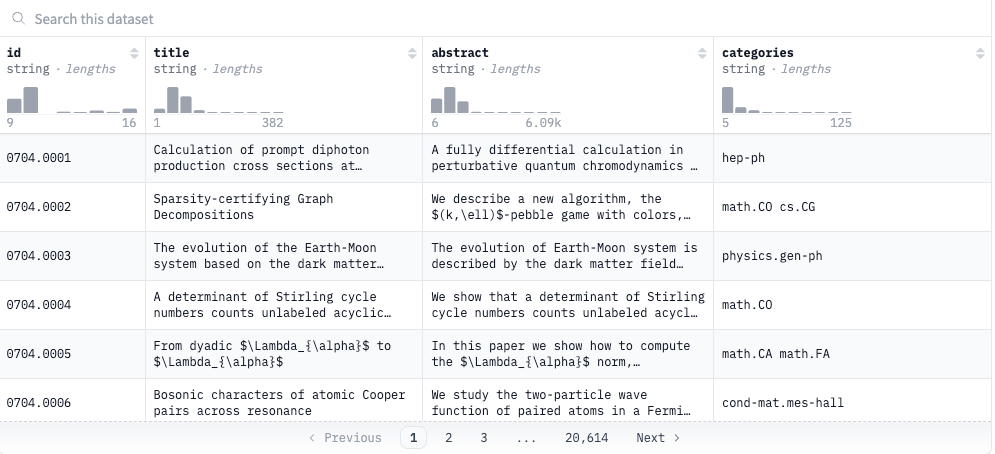
We utilize the raw cluster label datasets raw_arxiv, raw_biorxiv and raw_medrxiv datasets from MTEB Huggingface datasets and filter out common content from the MTEB evaluation set of {Arxiv/Biorxiv/Medrxiv}-Clustering-{S2S/P2P} tasks.
- S2S dataset을 target으로 할 때는 record에서
titlefield로 , P2P dataset을 target으로 할때는 record에서abstractfield로
categoryfield를 또는categoriesfield에서 random sample해서 , 로 선택된categoryfield의 value와 다른 value들 중에서 random sampling하여 를 구성함.
- 기준으로 stratified sampling을 수행하여 사용함.example: raw_arxiv, raw_biorxiv, raw_medrxiv
- S2S dataset을 target으로 할 때는 record에서


- STS dataset은 아래와 같이 사용함.
We use the training splits of three semantic similarity datasets STS12 (Agirre et al., 2012), STS22 (Chen et al., 2022), STS-Benchmark (Cer et al., 2017) from MTEB Huggingface datasets.
- record는 로 구성되어있음.
- 이상인 record로 , 를 구성함.
- hard negatives 는 기준으로 BM25로 얻어냄.
from the pool of all texts using BM25, selecting the highest matching texts with rank >=2 that do not have relevance scores >2.5 with .
Experiments
Experimental Details
- decoder-only LLM 부분은
LoRA로 학습함We train Mistral 7B LLM model end-to-end with a contrastive loss using LoRA with rank 16, alpha 32 and dropout rate of 0.1.
latent attention layer는 8개의 multi-head attentions으로 구성, 4096 hidden dimension size (single head)와 512 latents로 이루어짐.- ,
- single로 생각하면 4096 hidden dimension
- ,
- contrastive loss로
two-stage contrastive instruction-tuning으로 아래와 같이 학습함.We use Adam optimizer with 500 warm-up steps and learning rate 2e-5 for first stage and 1.5e-5 for second stage with linear decay. The model is finetuned with 128 batch size, where each batch is composed of a query paired with 1 positive and 7 hard negative documents. We train using Bfloat16, and set the maximum sequence length as 512 tokens. The special <BOS> and <EOS> tokens are appended at the start and end of given query and documents. The whole training is conducted in two stages where the model is initially trained on retrieval datasets utilizing in-batch negative technique. Subsequently, the model is trained with blended datasets with both retrieval and non-retrieval embedding tasks.
- evaluation을 할 때는 maximum length를 512로함.
MTEB Results
Ablation Study
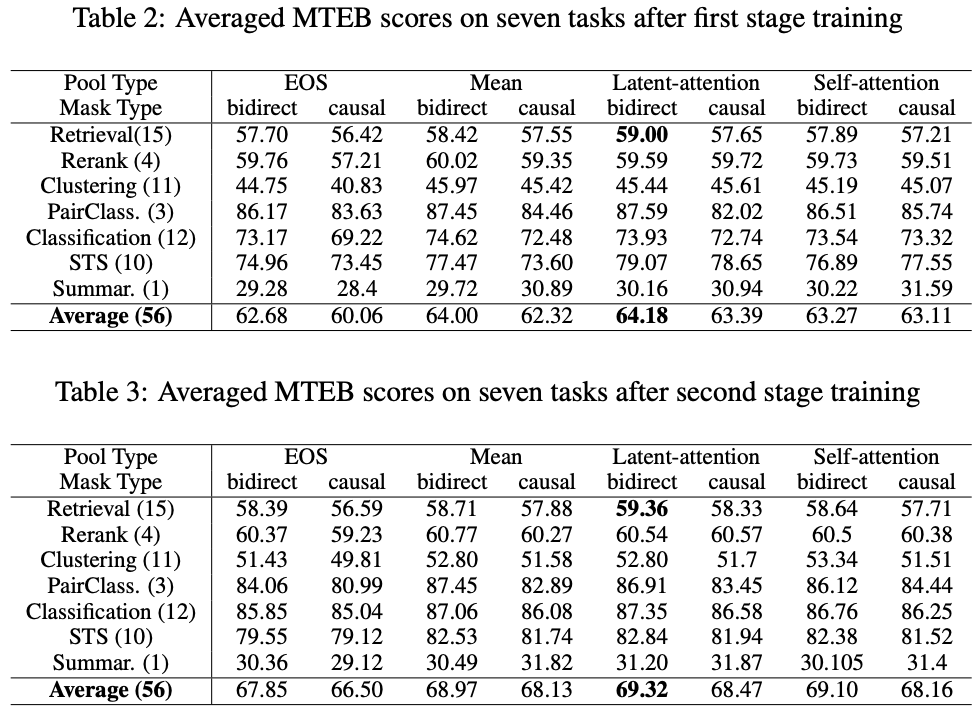
- pooling method에 관계 없이 bidirectional attention이 항상 좋음을 알 수 있음.
mean pooling이<EOS>-last token embedding보다 attention type에 상관없이 더 좋음을 알 수 있음.<EOS>-last token embedding은 recency bias 존재함.
mean pooling은 key phrases의 information은 희석하는 문제가 존재함.
- 제안한
latent attention layer가self attention layer를 하나 더하는 방식보다 우수함.This is not surprising, as the LLM already has many self-attention layers to learn the representation, and adding an additional one does not bring significant additive value.
latent attention layer의 latent array가 일종의 좋은 representation의 attributes를 학습을 통해 정의했다고 추측하는 관점 인듯?We hypothesize that this is due to the "dictionary learning" provided by the latent array, which offers more expressive representation. The latent-attention layer effectively learns output embedding representations from decoder-only LLMs, mitigating the information dilution caused by averaging the output embeddings.