Key Insights Behind Phi-2
phi-1.5와 동일한 방향으로 진행하돼, model의 scale과 학습에 사용한 dataset을 확장하여phi-2.0을 학습함.Our training data mixture contains synthetic datasets specifically created to teach the model common sense reasoning and general knowledge, including science, daily activities, and theory of mind, among others. We further augment our training corpus with carefully selected web data that is filtered based on educational value and content quality.
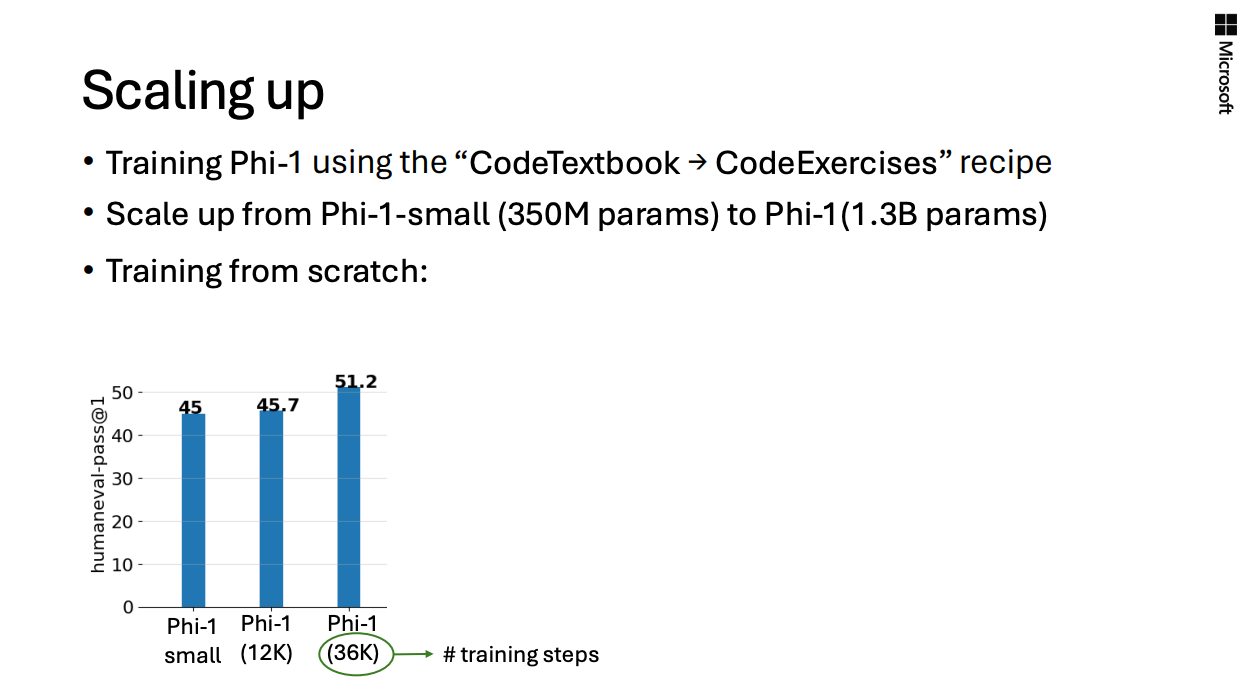
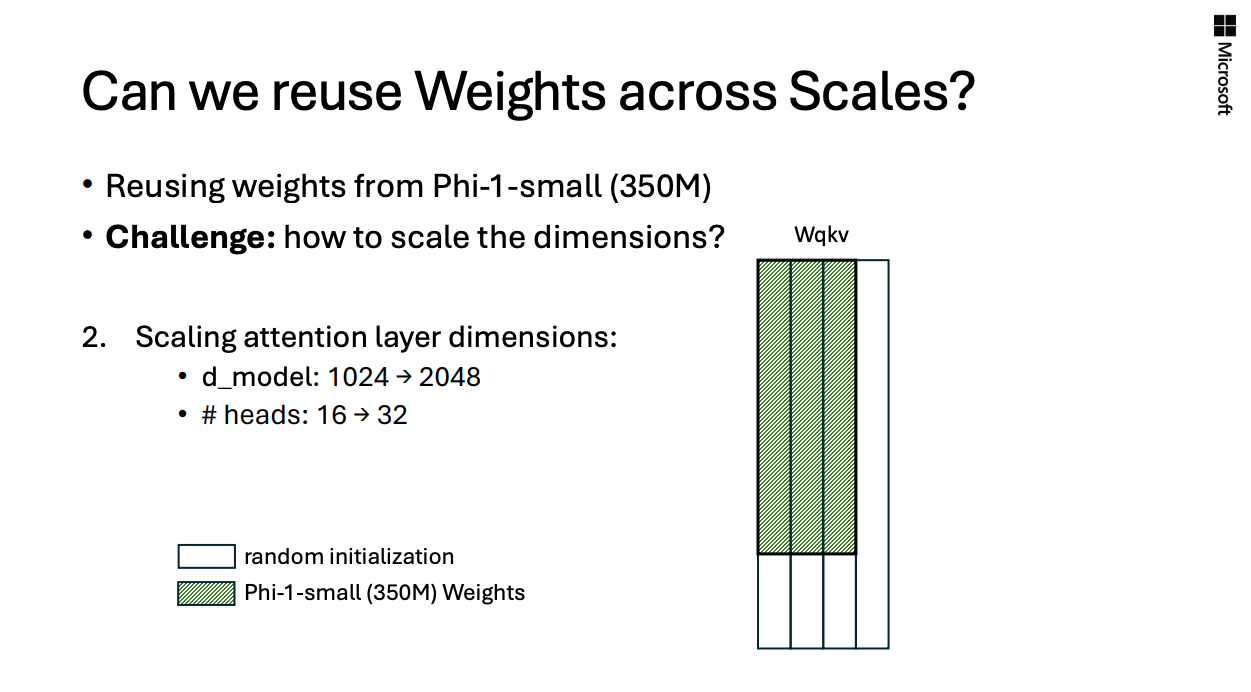
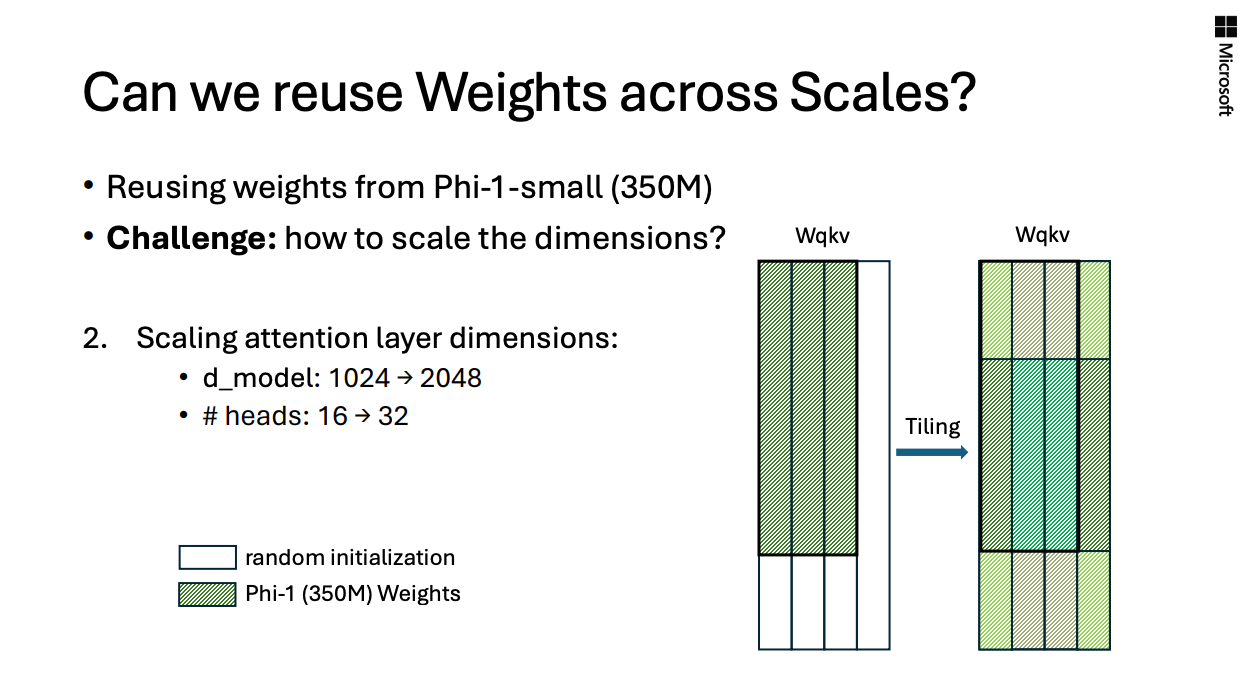
phi-2.0(2.7B)으로 model scale을 확장하는 방법으로,phi-1.5의 weight를 reuse하고 tiling을함.- 해당 내용이
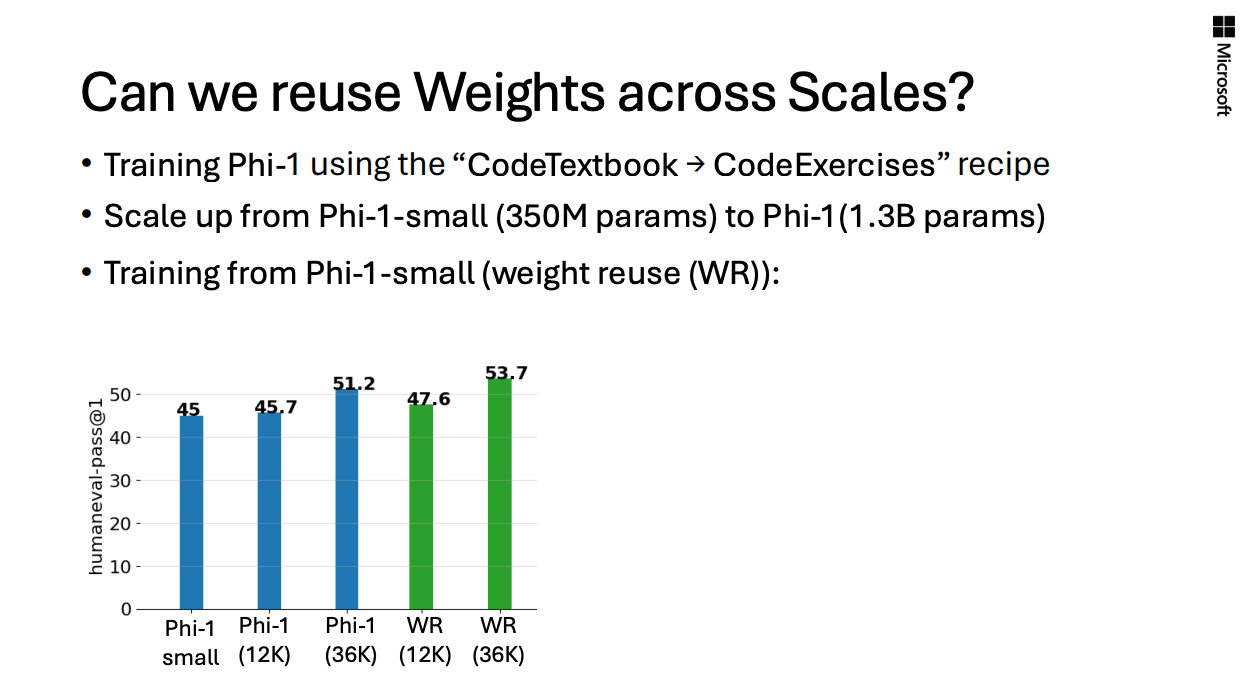
phi-1.0의 paper에는 없지만, 이를phi-1.0-small(350M),phi-1.0(1.3B)으로 weigh reuse, tiling하는 실험이 존재했고, 이를 뉴립스에서 발표했었음.in NeurlIPS 2024
- 해당 내용이


Training Details & Phi-2 Evaluation
Training Details
Phi-2 is a Transformer-based model with a next-word prediction objective, trained on 1.4T tokens from multiple passes on a mixture of Synthetic and
Web datasets for NLP and coding. The training for Phi-2 took 14 days on 96 A100 GPUs. Phi-2 is a base model that has not undergone alignment
through reinforcement learning from human feedback (RLHF), nor has it been instruct fine-tuned.
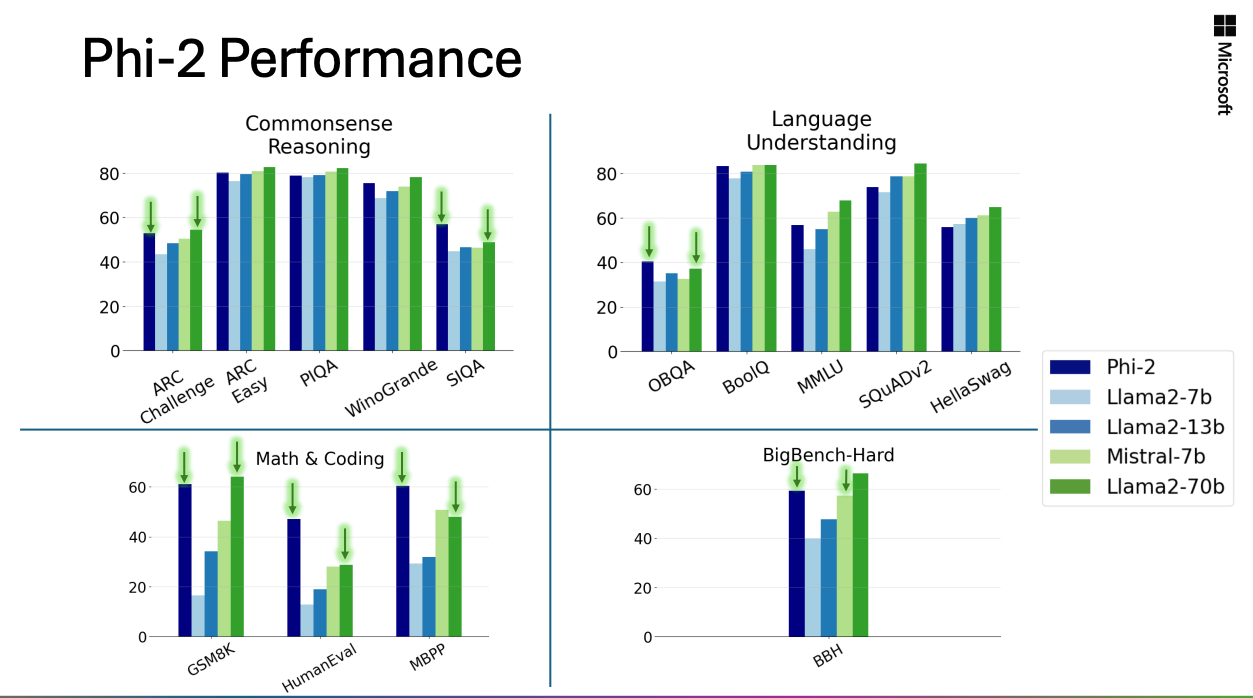
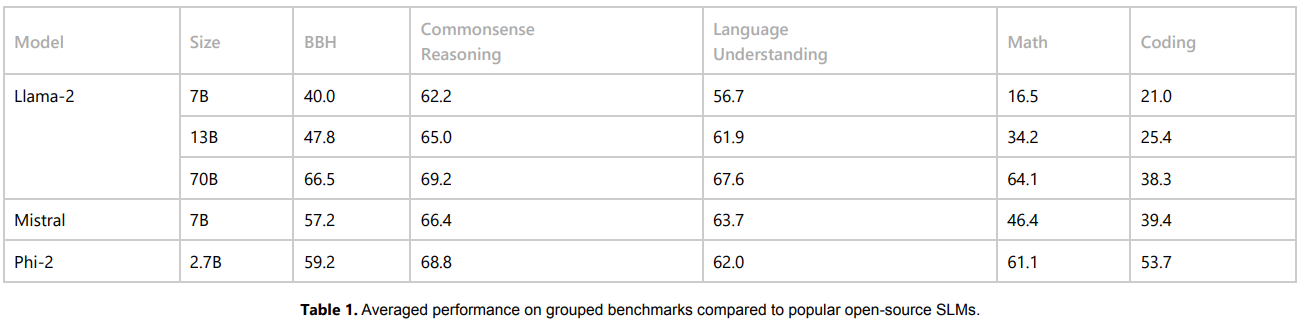
Phi-2 Evaluation