Abstract
phi-2.0에서의 기조를 그대로 이어가돼,phi-3-mini(3.8B),phi-3-small(7B),phi-3-medium(14B)를 통해서 parameter-scaling 결과를 공개함.phi-3-mini(3.8B)는 3.3T tokens로 학습
phi-3-small(7B)와phi-3-medium(14B)는 4.8T tokens로 학습
- 이전 model series과 달리 alignment를 진행한 version 같이 공개함.
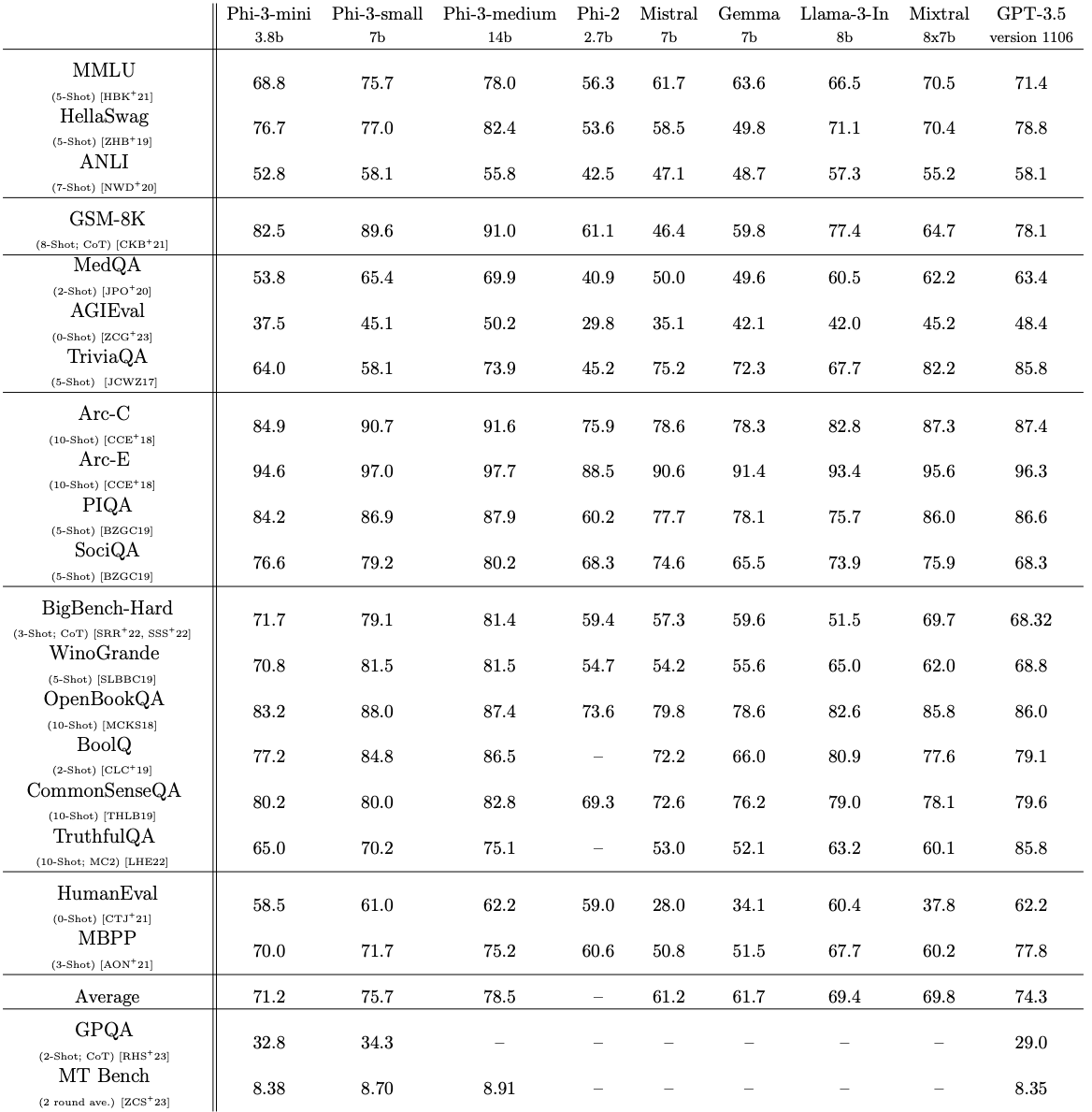
phi-3-mini→phi-3-small→phi-3-medium에 따라서, (MMLU, MT-bench) 성능이 (69, 8,38) → (75, 8.7) → (78, 8.9)
- 또한
phi-3-mini(3.8B)를 기초로한,phi-3-vision(4.2B, image-text input, text output)을 공개함.
Introduction
- 이전 model series (
phi-1,phi-1.5,phi-2)의 기조를 더욱 확장하여 진행In our previous works on the phi models [GZA+23, LBE+23, JBA+23] it was shown that a combination of LLM-based filtering of publicly available web data, and LLM-created synthetic data, enable performance in smaller language models that were typically seen only in much larger models
phi-2대비,phi-3-mini는 model size는 2.7B → 3.8B로 train tokens는 1.4T → 3.3T로 확장함.
- 특히
phi-3-mini가 mobile환경에서 동작하며 그 성능은 GPT-3.5, Mixtral 8x7B와 비교할만한 수준임을 강조함.
Technical Specifications
Model
- common
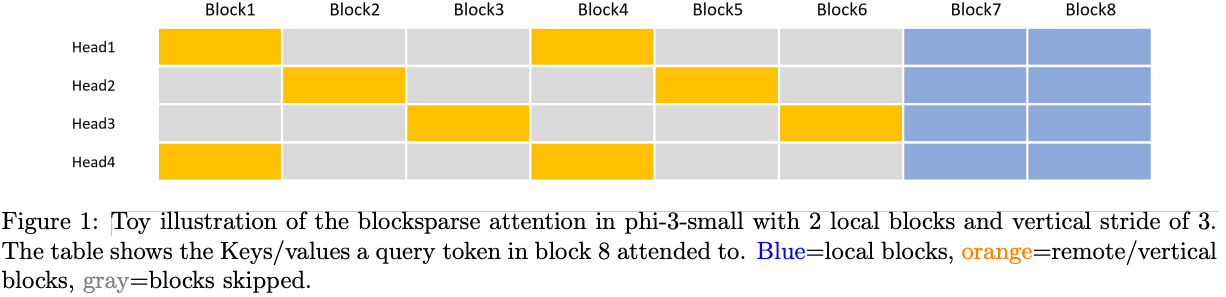
- model에 상관없이 context length를 확장할 때는 LongRoPE라는 방법론을 사용함.
phi-3-mini phi-3-small
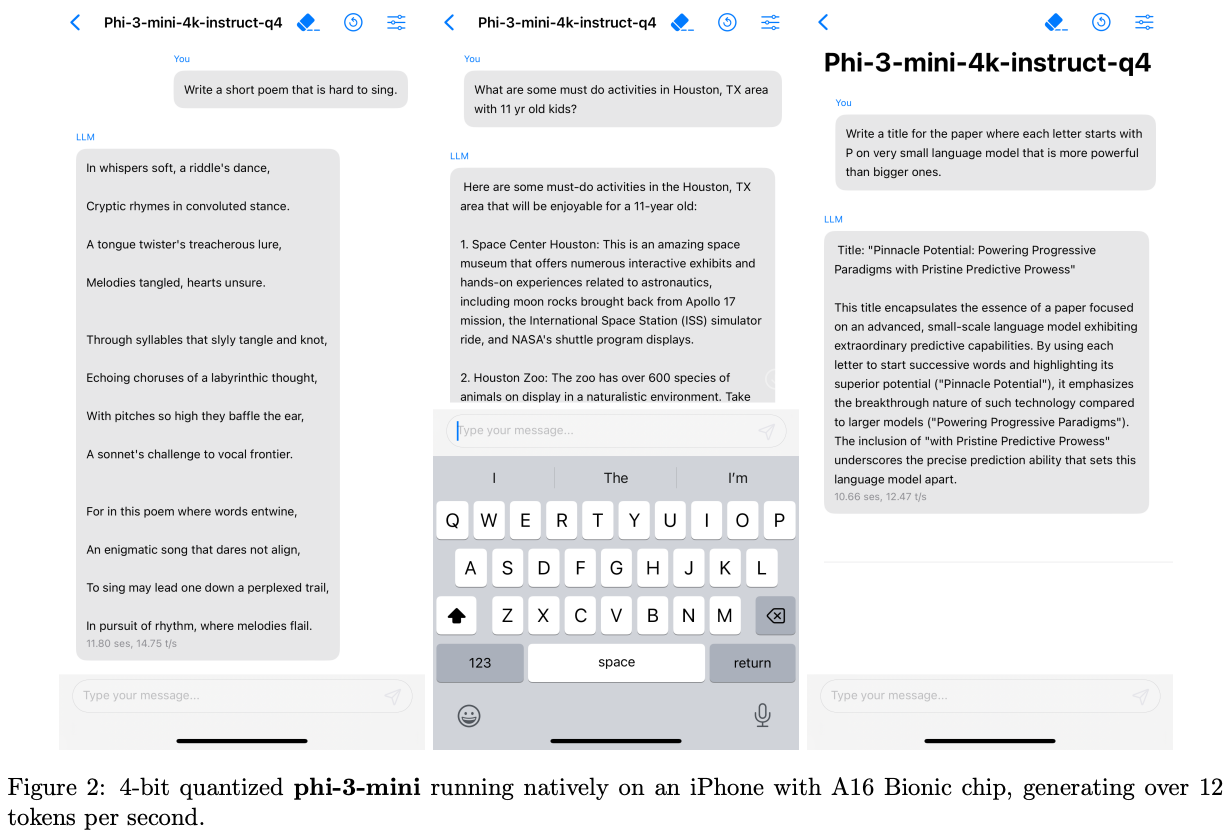
phi-3-mediumHighly capable language model running locally on a cell-phone
Thanks to its small size, phi3-mini can be quantized to 4-bits so that it only occupies ≈ 1.8GB of memory. We tested the quantized model by deploying phi-3-mini on iPhone 14 with A16 Bionic chip running natively on-device and fully offline achieving more than 12 tokens per second.
Training Methodology
pre-training
post-training
Data Optimal Regime
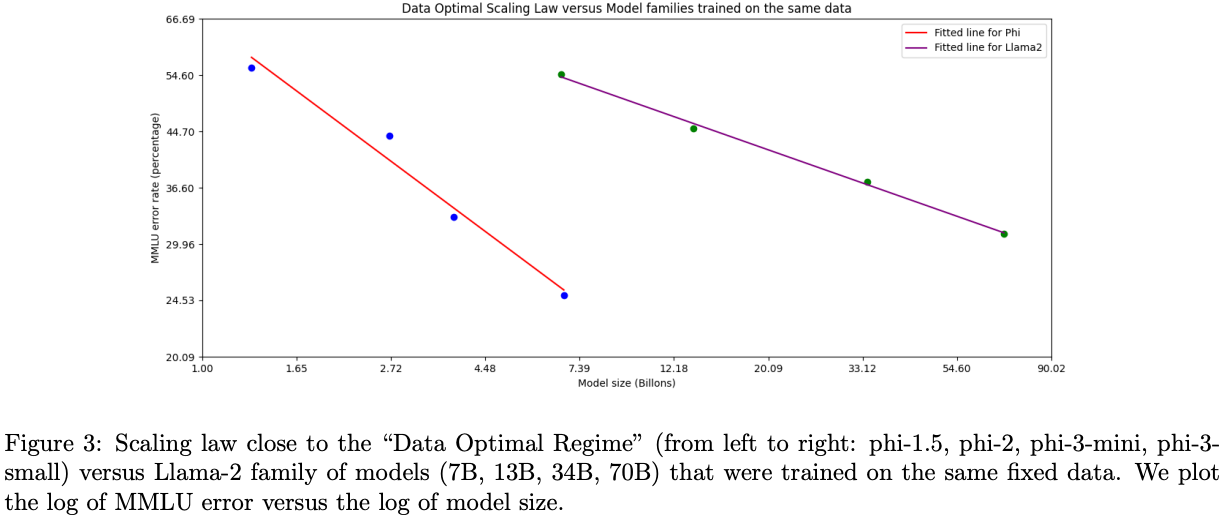
- small scale의 LLM에서는 reasoning ability를 학습시켜 줄 수 있는 data가 훨씬 중요함.
We try to calibrate the training data to be closer to the “data optimal” regime for small models. In particular, we filter the publicly available web data to contain the correct level of “knowledge” and keep more web pages that could potentially improve the “reasoning ability” for the model. As an example, the result of a game in premier league in a particular day might be good training data for frontier models, but we need to remove such information to leave more model capacity for “reasoning” for the mini size models.
- larger scale의 LLM에서는 factual knowledge도 중요한 data가 됨.
We observe that some benchmarks improve much less from 7B to 14B than they do from 3.8B to 7B, perhaps indicating that our data mixture needs further work to be in the “data optimal regime” for 14B parameters model.
Academic benchmarks
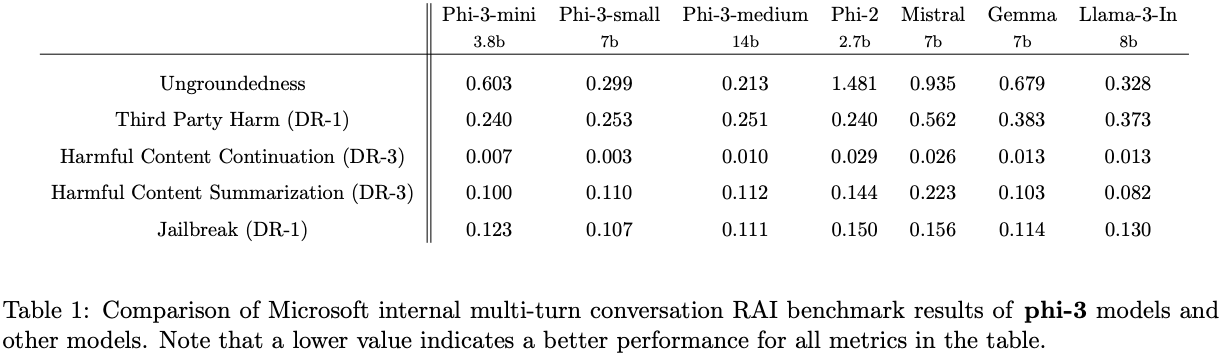
Safety & Weakness
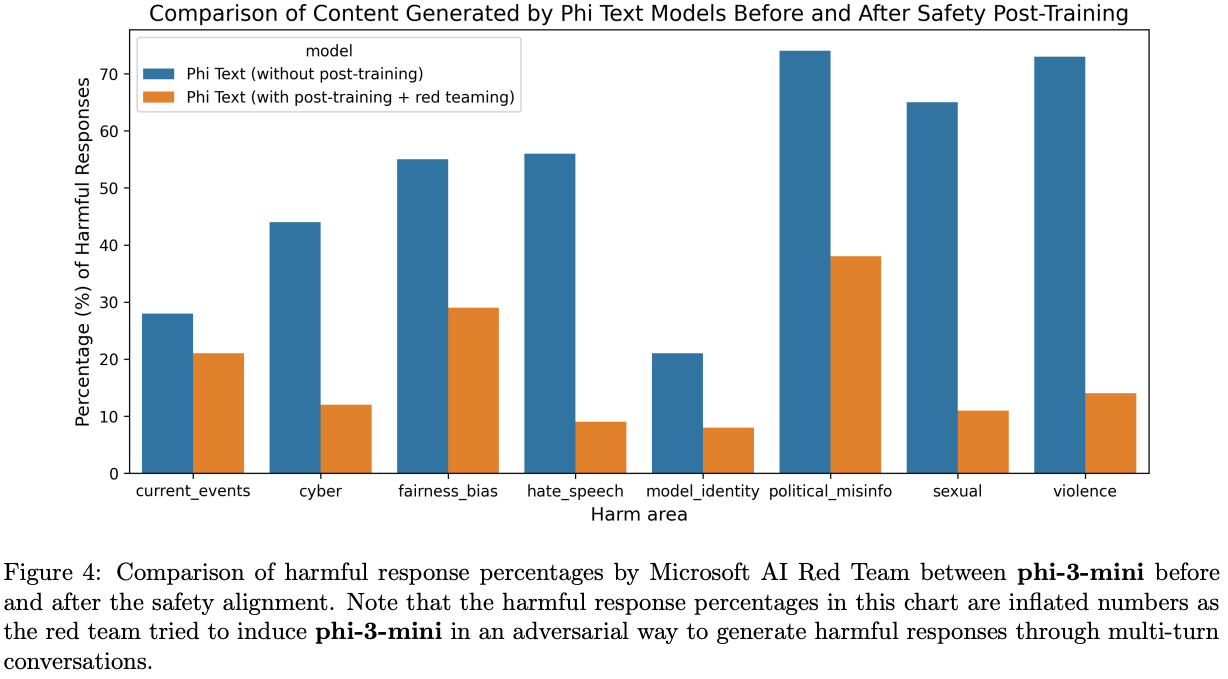
phi-3-mini가 factual knowledge or hallucination관련해서phi-3-small,phi-3-medium대비 문제가 조금 있음을 알 수 있음.💡data-optimal-regime과 관련한 문제라고 생각함. larger scale의 LLM이 factual knowledge를 학습하는 것이, small scale의 LLM보다 훨씬 쉬움. → reasoning과 관련된 ability를 적당한 scale에서 획득하고, 그 이후의 size 증대는 factual knowledge 획득으로 hallucination을 감소시킬 수 있다..?
phi3-mini의 경우, search engine과 잘 섞으면 이를 개선할 수 있음.
